Parallel Bibles
Question
How do the world's languages encode the temporal relations expressed by English when-clauses? Why can languages that possess a direct equivalent of when not always use it in the same contexts? Can we identify a finite set of functional patterns among the world's languages that explain this variation?Challenge
Typological studies of specific constructions traditionally rely on manually annotated parallel corpora covering a limited number of languages. Scaling this approach to hundreds or thousands of languages then presents some challenges:- How can we analyse much larger language samples without manual annotation?
- Can we detect functional patterns in a data-driven way, without predefining semantic categories?
- Can meaningful typological groupings emerge even for languages unfamiliar to the researcher?
Data
The Bible is the most widely translated book in history. To maximize language coverage, we used Mayer & Cysouw's (2014) massively parallel Bible corpus, which contains the New Testament in over 1400 linguistic varieties. To include ancient languages, we also added the Latin, Classic Armenian, Gothic, and Old Church Slavonic translations of the New Testament from the PROIEL treebanks (Haug & Jøhndal 2008).(Pre-)processing and alignment at token-level
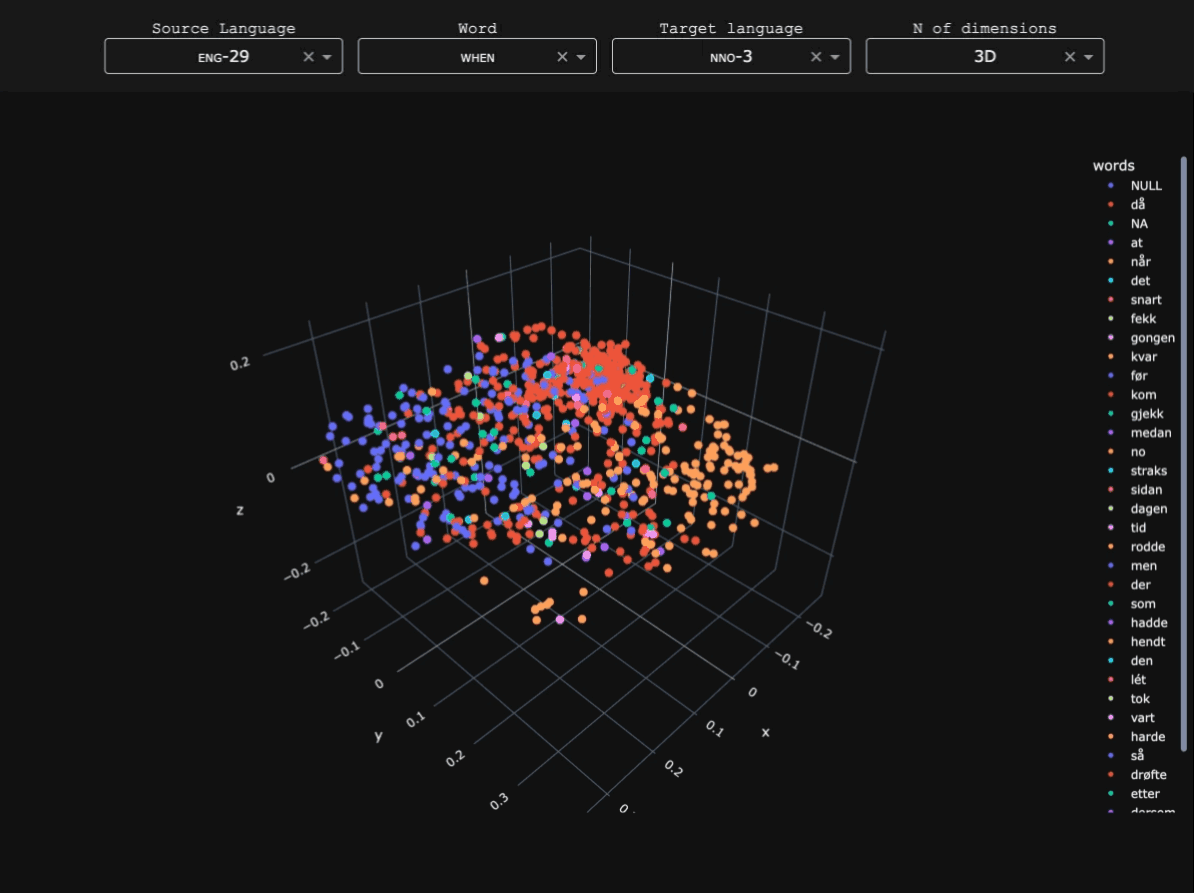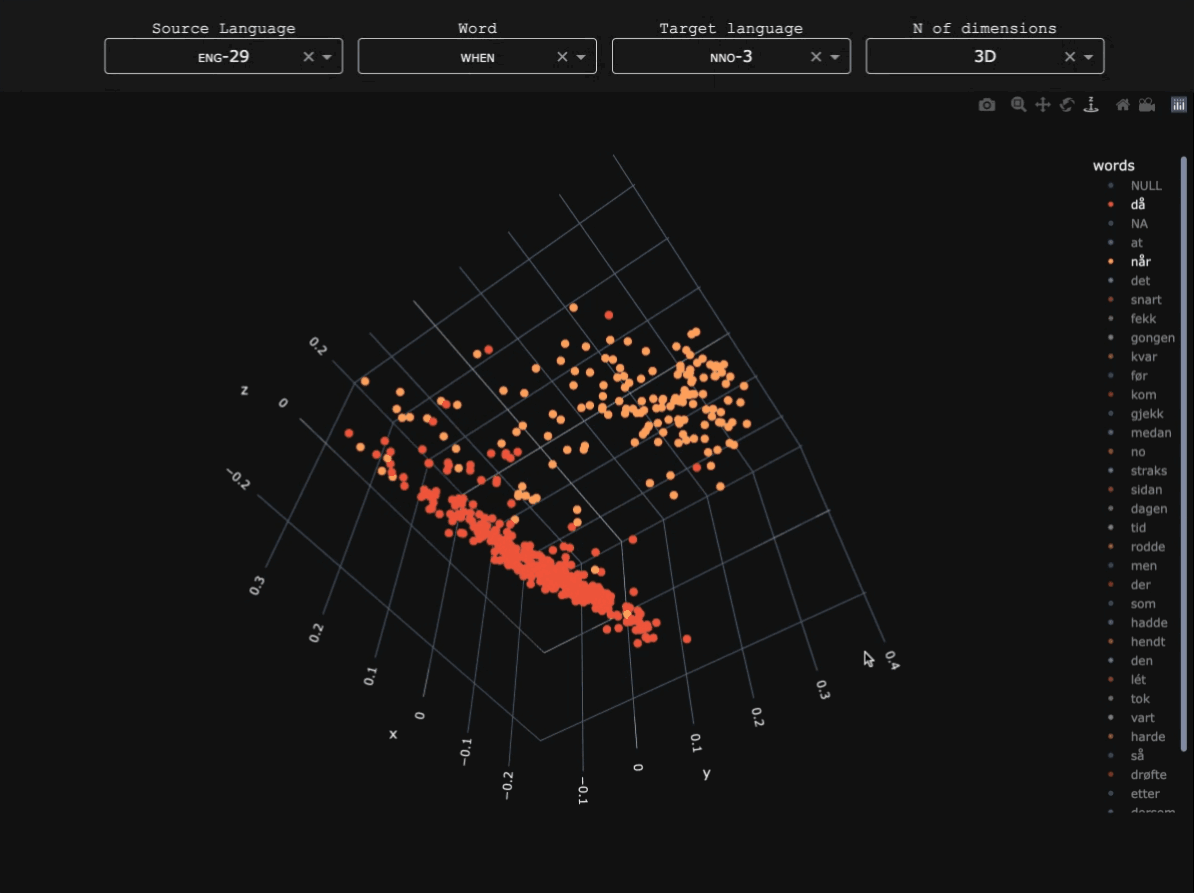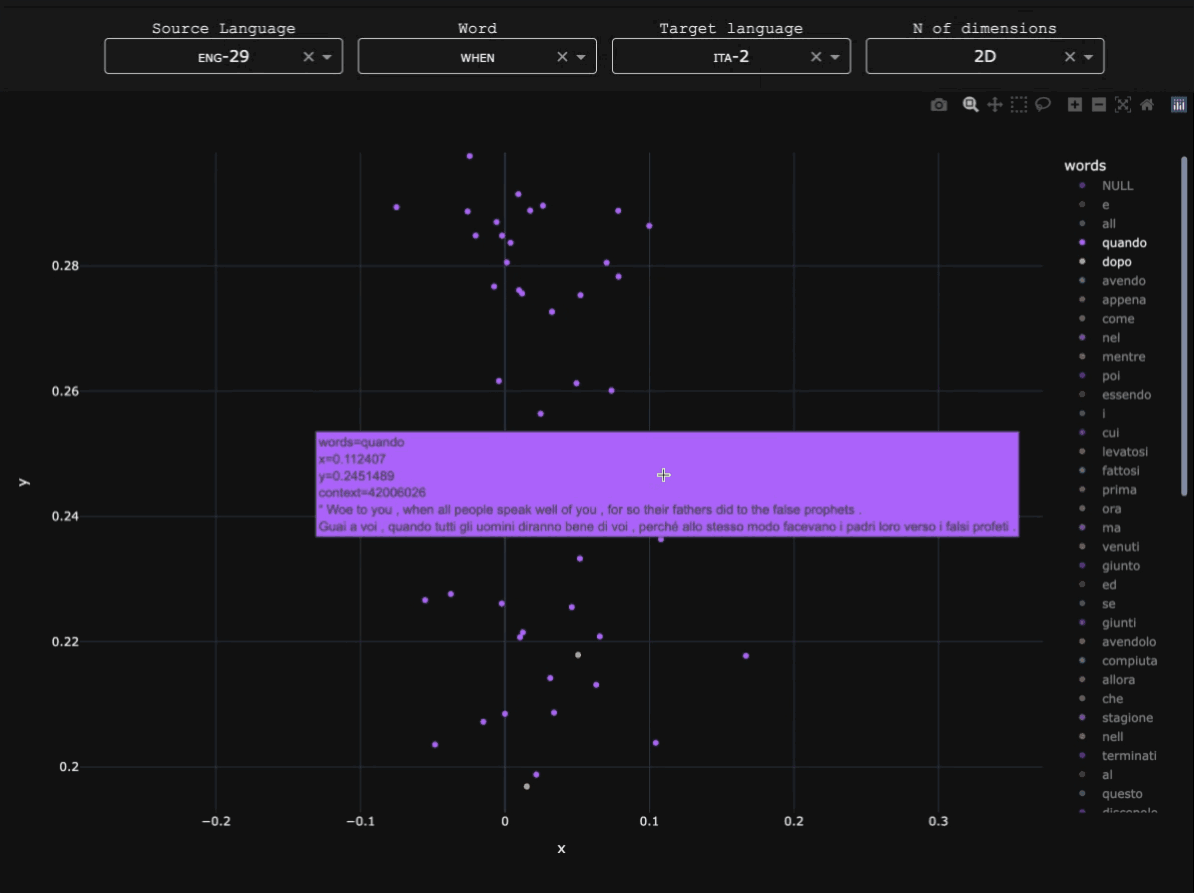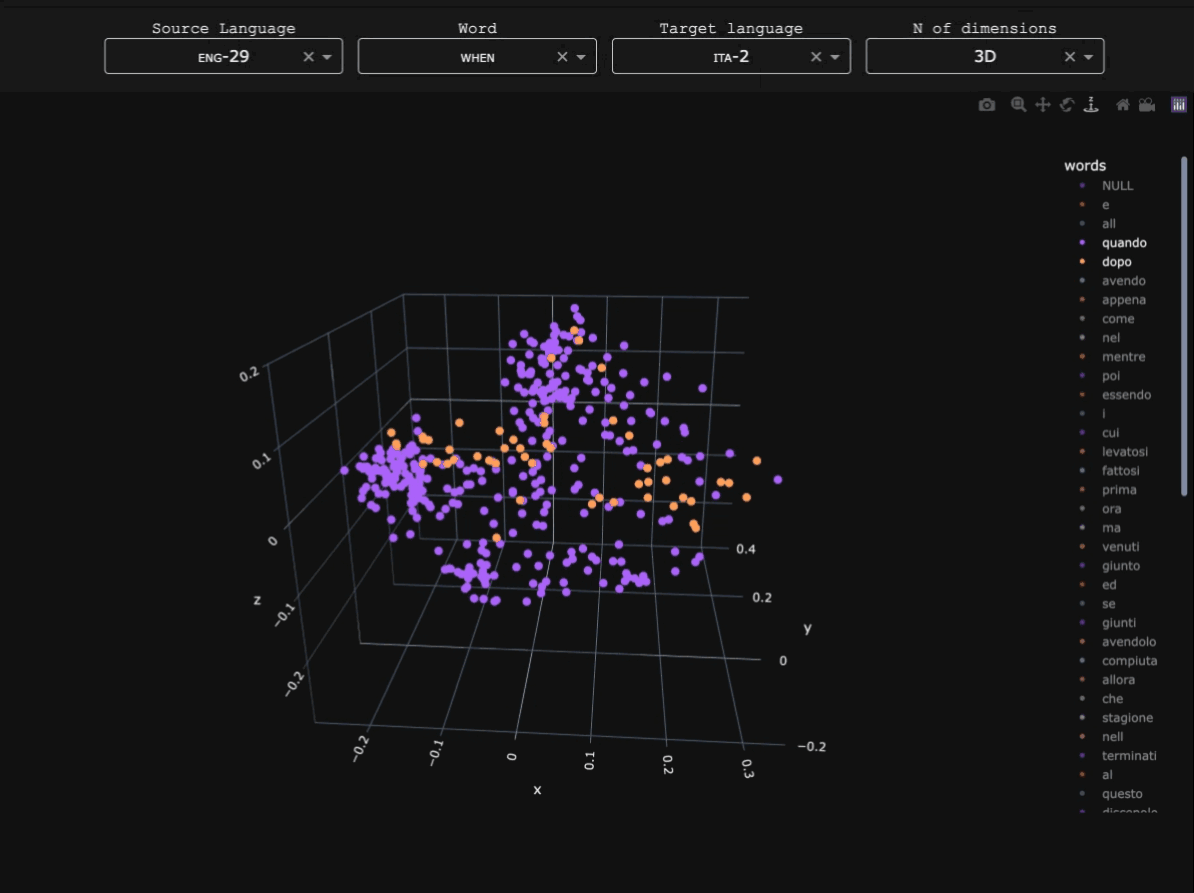
For each language, word alignments with English were obtained using SymGIZA++ (Junczys-Dowmunt & Szał 2012), after comparison with other alignment tools such as GIZA++ and FastAlign. Minimal preprocessing (lowercasing and punctuation removal) was applied before training.Token-level alignment
For each language, word alignments with English were obtained using SymGIZA++ (Junczys-Dowmunt & Szał 2012), after comparison with other alignment tools such as GIZA++ and FastAlign. Minimal preprocessing (lowercasing and punctuation removal) was applied before training.Similarity matrix and dimensionality reduction
After extracting when and its parallels across the corpus, Hamming distance was used to measure similarity between contexts, based on how often languages use different constructions where English uses when. Principal coordinate analysis (i.e. classical metric multidimensional scaling) was then applied to visualize the resulting distance matrix. The further away two points, the more common it is for them to be coexpressed by the same construction crosslinguistically. Below is the 3D example for Pular, a Fula (Atlantic-Congo) language of Guinea which possesses several words for 'when'.From individual observations to widesread functional domains
Clusters of semantically similar contexts were identified by fitting Gaussian Mixture Models (GMM) to the MDS matrix. Model-selection heuristics (elbow, silhouette, and Davies-Bouldin scores) suggest that around three clusters capture the main structure of the data, while larger numbers begin to overfit. These clusters can be interpreted as broad functional domains of when commonly coexpressed across languages.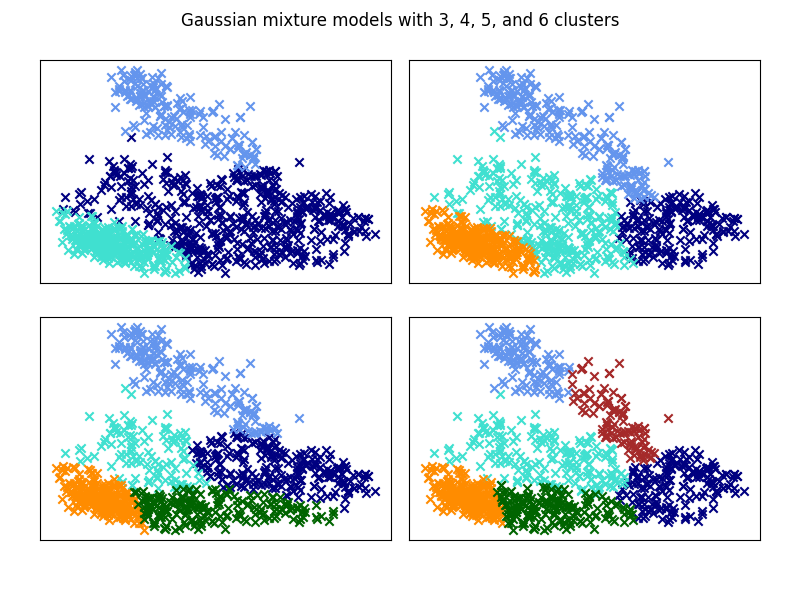
From widespread domains to language-internal variation
Starting from the MDS matrix, Kriging was used as an interpolation method to estimate the areas in the semantic map where a particular construction is most likely to occur in a given language. While GMM identifies cross-linguistic functional clusters, Kriging helps discovering how individual languages distribute their constructions across those functional domains. For example, Norwegian uses a single construction across two clusters GMM clusters, whereas Kako distinguishes them with two different markers (ma and ŋgimɔ).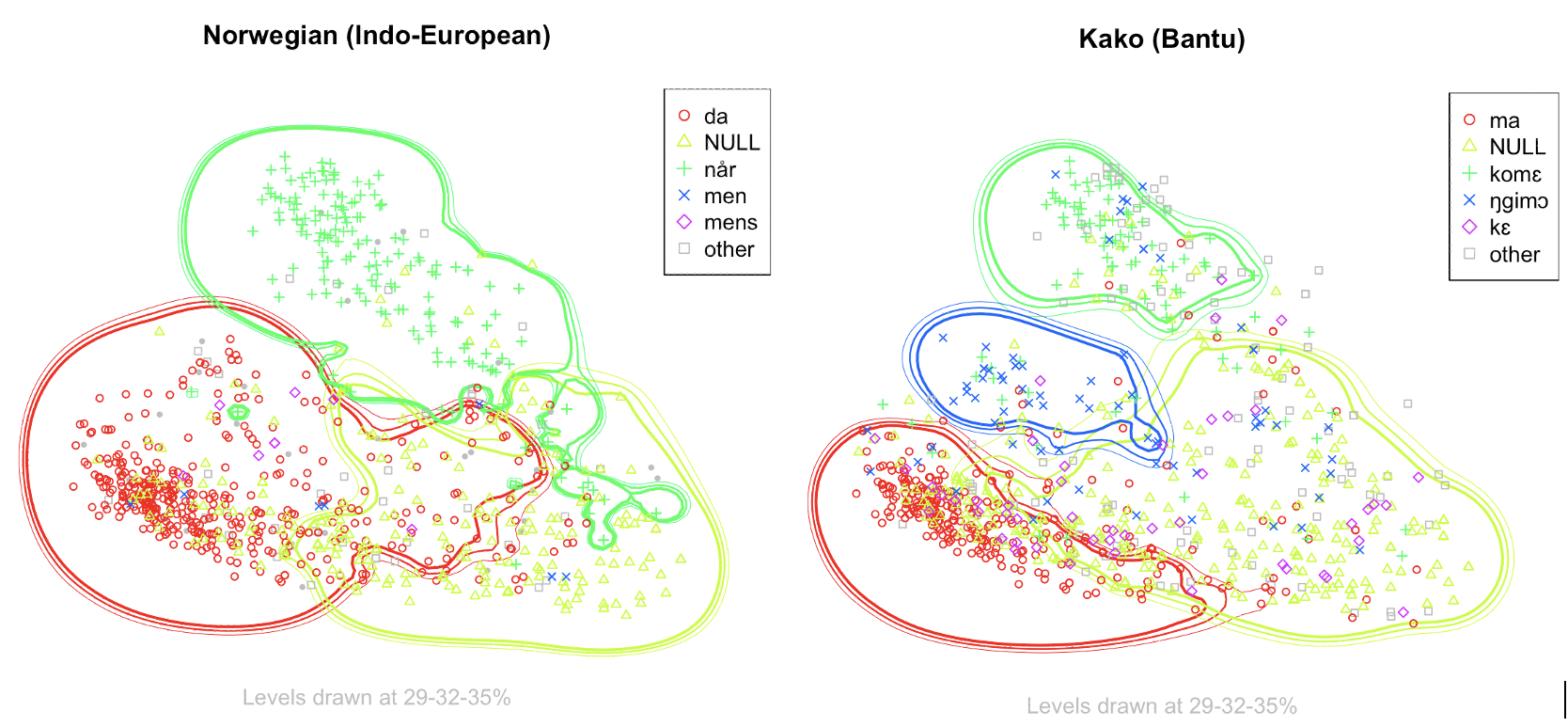
More results
Curious about how maps such as the Norwegian and Kako ones above were used to analyse all the other languages in the corpus typologically? Check out the article The semantic map of when and its typological parallels coauthored with Dag Haug and my PhD thesis.
Want to know how we could automatically detect and represent variation among constructions encoded at the morphological, subtoken level (e.g. switch referece markers, converbs, participles, etc.) in the semantic maps? Check out my experiments on when-clauses and switch-reference morphology described in the article Mapping 'when'-clauses in Latin American and Caribbean languages: an experiment in subtoken-based typology.
Credits
This is a project in collaboration with Prof. Dag Haug (Oslo).References
D. T. T. Haug & M. L. Jøhndal. 2008. Creating a parallel treebank of the old Indo-European Bible translations. In Proceedings of the Second Workshop on Language Technology for Cultural Heritage Data (LaTeCH 2008), pages 27–34.
D. T. T. Haug & N. Pedrazzini. 2023. The semantic map of when and its typological parallels . Frontiers in Communication, 8.
N. Pedrazzini. 2023. A quantitative and typological study of Early Slavic participle clauses and their competition . PhD thesis, University of Oxford.
M. Junczys-Dowmunt & A. Szał. 2012. SymGiza++: Symmetrized word alignment models for machine translation . In Pascal Bouvry, Mieczyslaw A. Klopotek, Franck Leprévost, Malgorzata Marciniak, Agnieszka Mykowiecka & Henryk Rybinski (eds.), Security and Intelligent Information Systems (SIIS 7053), Lecture Notes in Computer Science, pages 379–390. Warsaw, Poland: Springer.
T. Mayer & M. Cysouw. 2014. Creating a massively parallel Bible corpus. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC 2014), pages 3158–3163. Reykjavik, Iceland: European Language Resources Association (ELRA).
N. Pedrazzini. 2024. Mapping ''when'-clauses in Latin American and Caribbean languages: An experiment in subtoken-based typology . In Proceedings of the 4th Workshop on Natural Language Processing for Indigenous Languages of the Americas (AmericasNLP 2024), pages 24-33. Mexico City, Mexico: Association for Computational Linguistics.
Check out other projects