Ancient Greek graph-based syntactic word embeddings
Overview
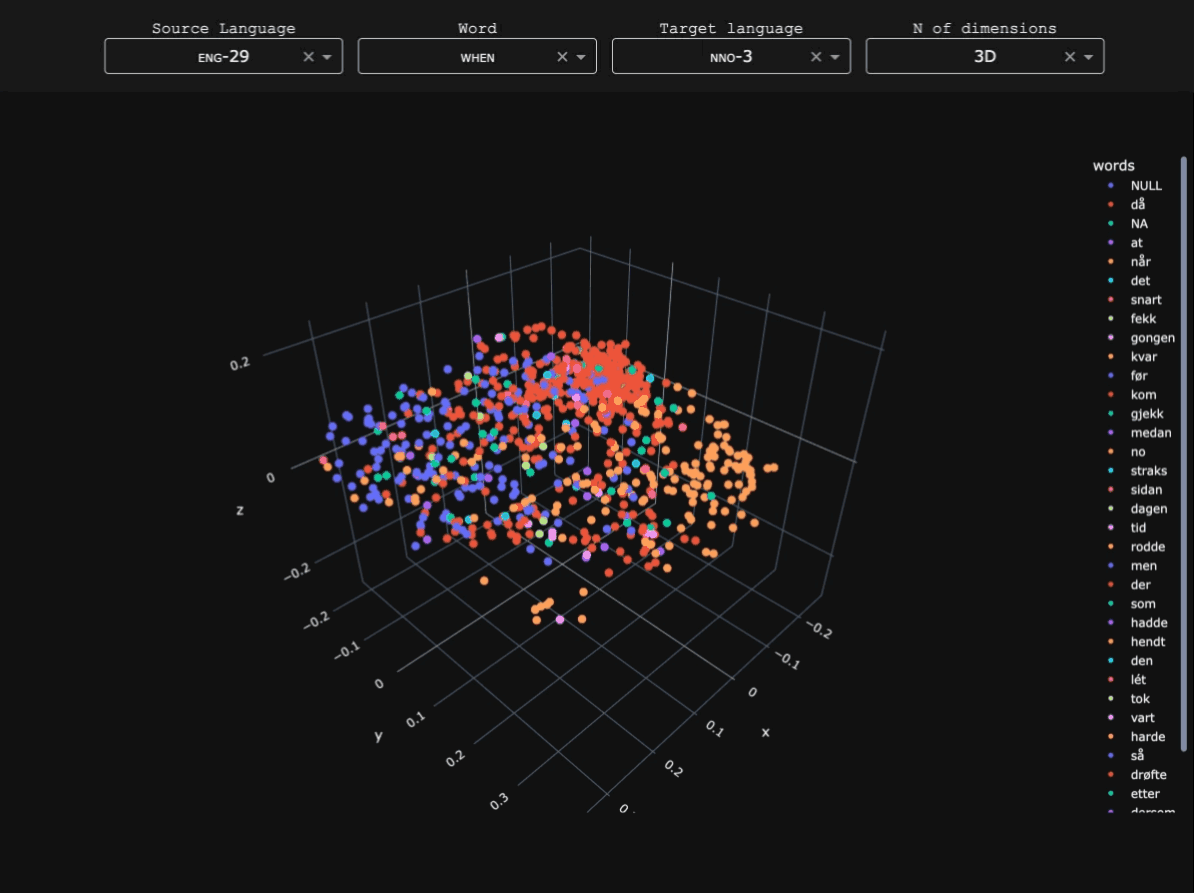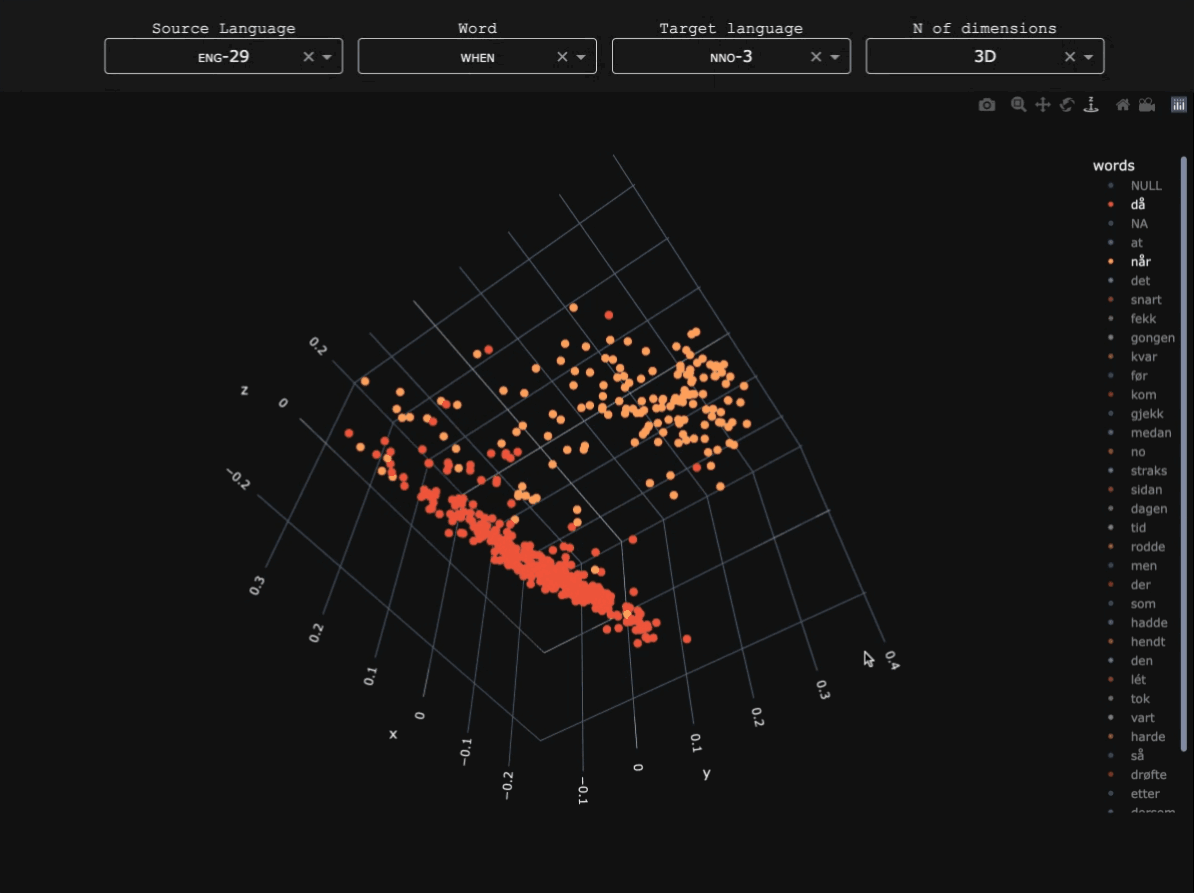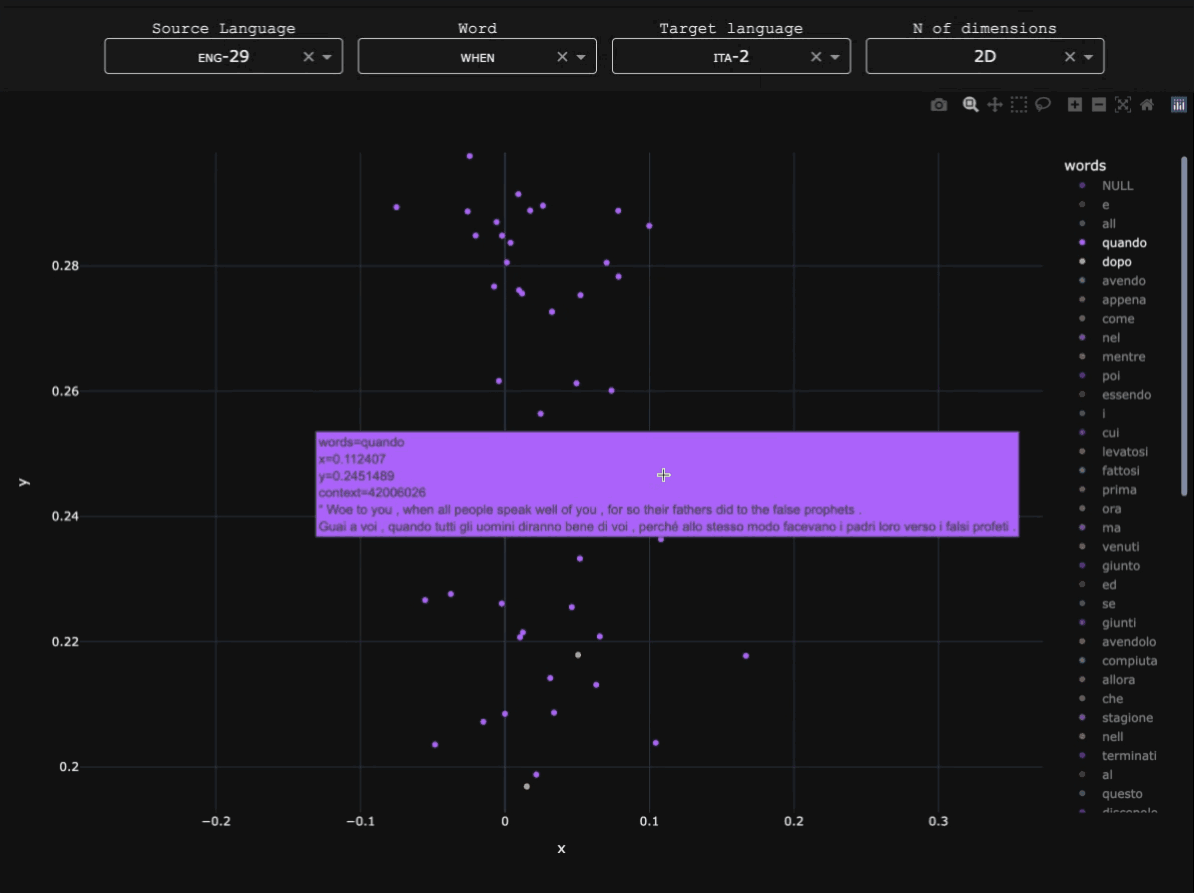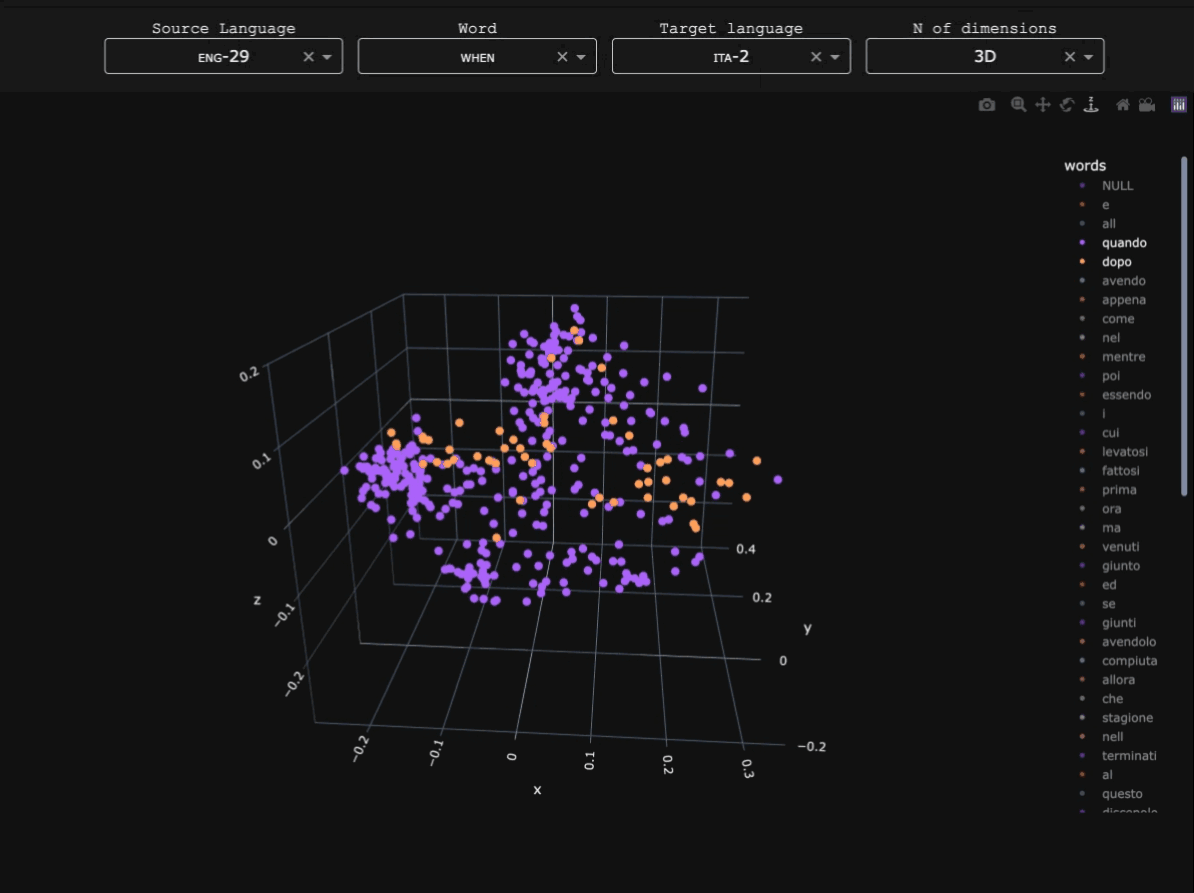
This experiment explored whether syntactic information from Ancient Greek dependency treebanks could be used to train graph-based word embeddings. Unlike standard distributional embeddings trained on linear context windows, syntactic embeddings derive relationships between words from their positions within dependency structures.
The goal was to explore how such representations capture different kinds of linguistic similarity, particularly functional or syntactic similarity between words. The experiment was conducted as part of a broader exploration of language modelling for Ancient Greek, and syntactic embeddings derived from this work were discussed in Stopponi et al. (2023) and Stopponi et al. (2024).Graph-based syntactic embeddings
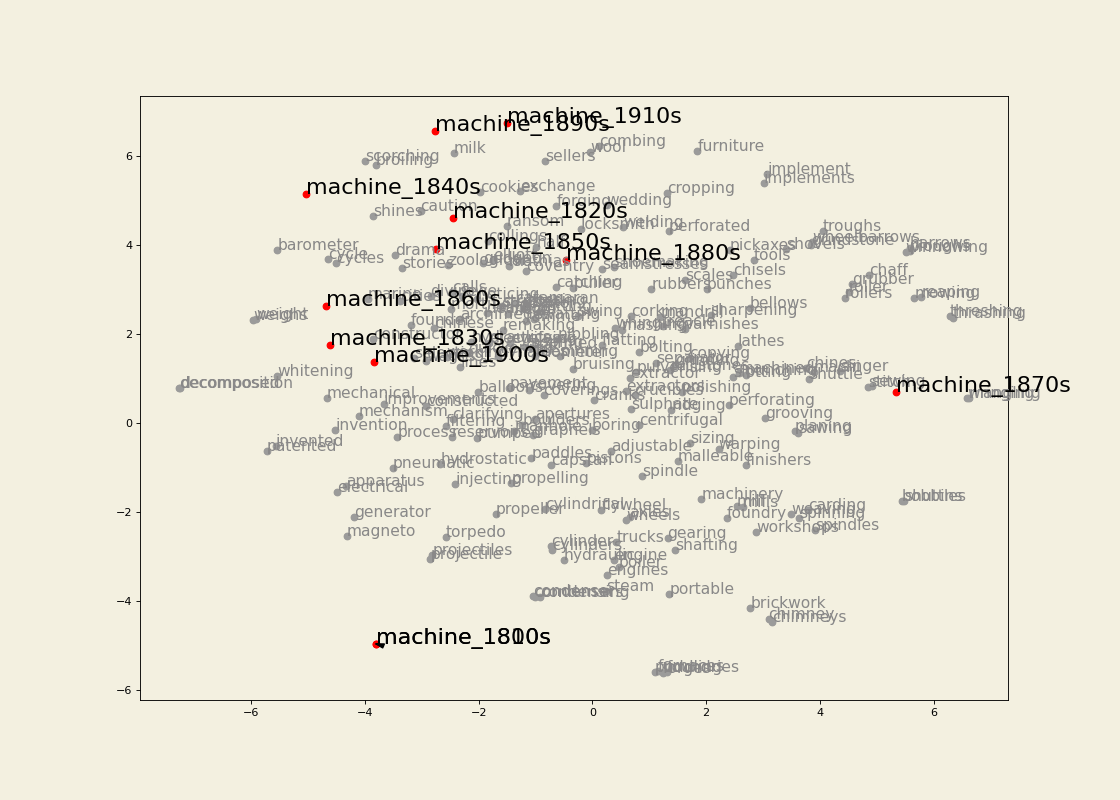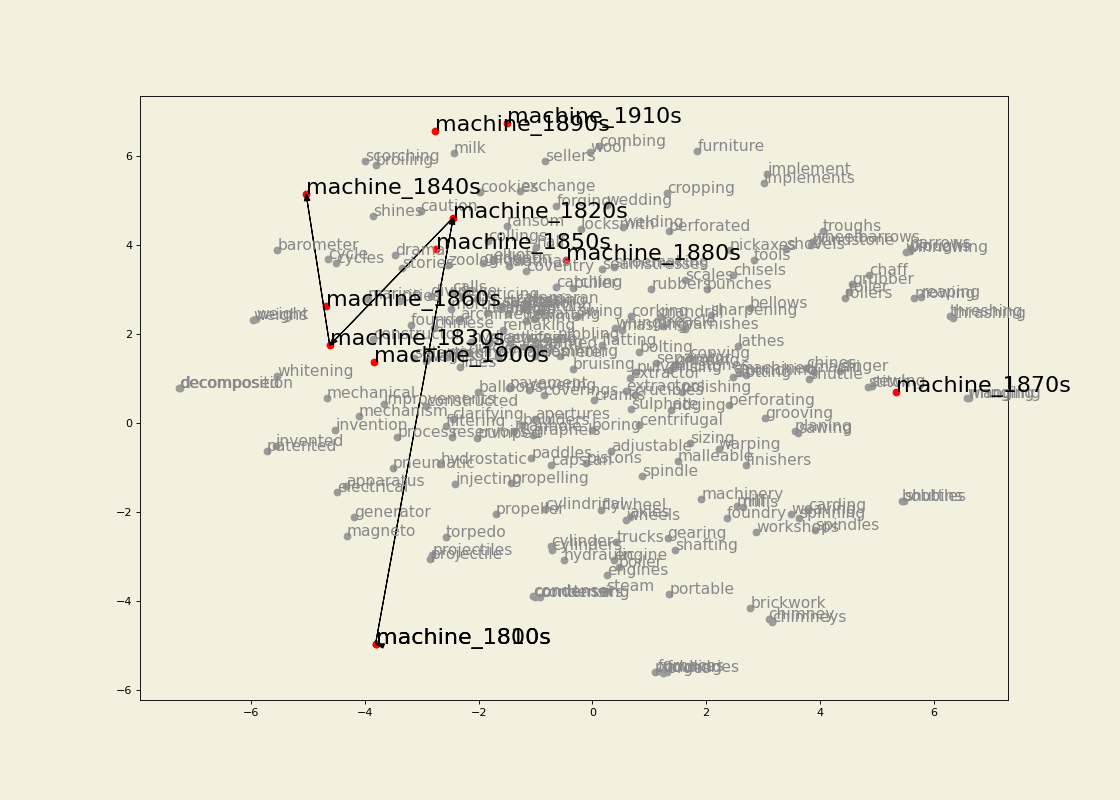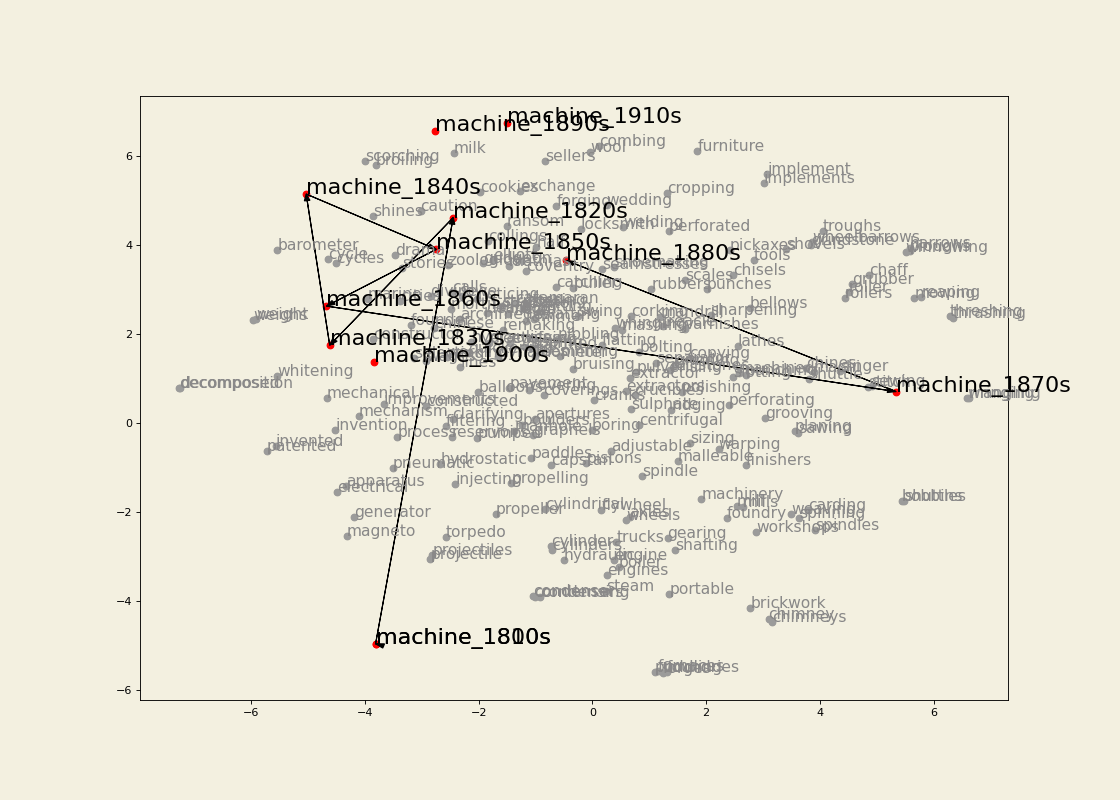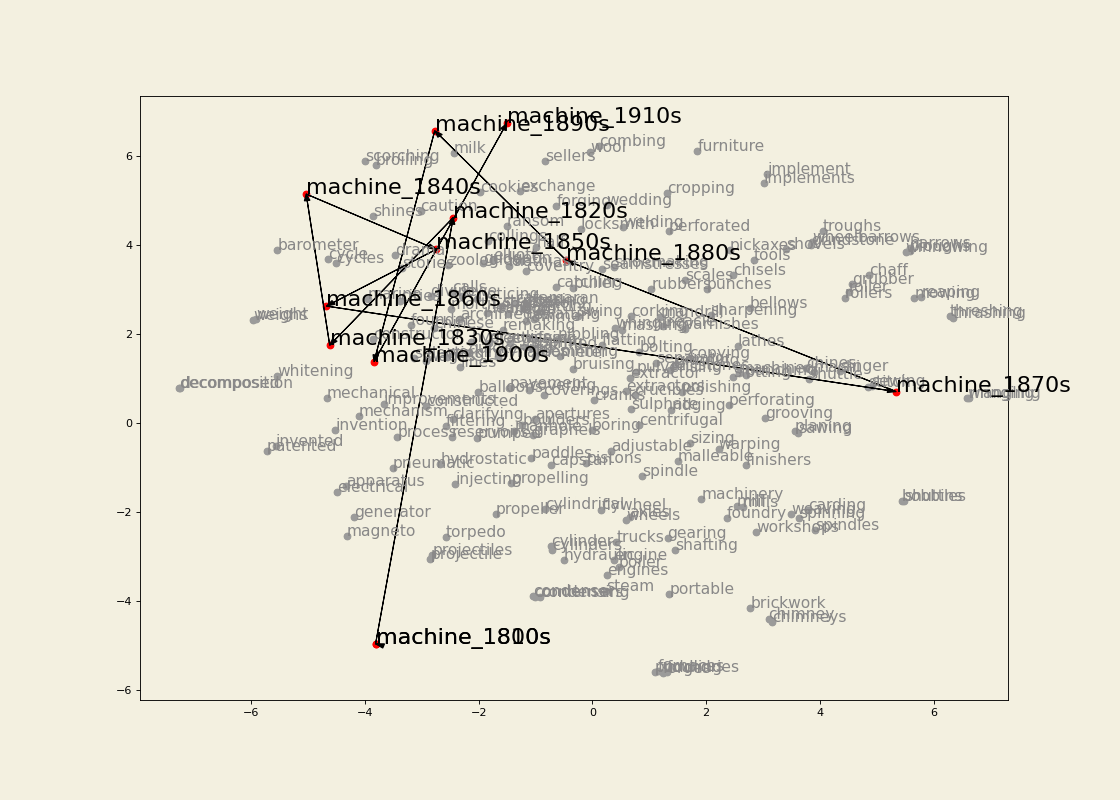
The embeddings were trained using a graph-based approach inspired by Al-Ghezi & Kurimo (2020). Dependency trees from several Ancient Greek treebanks were converted into graph structures and merged into a single supergraph representing syntactic relations across the corpus.
Word vectors were then learned for the nodes of this graph using node2vec. In this framework, a word's representation is determined by the syntactic neighbourhoods it appears in, rather than by linear co-occurrence within sentences.
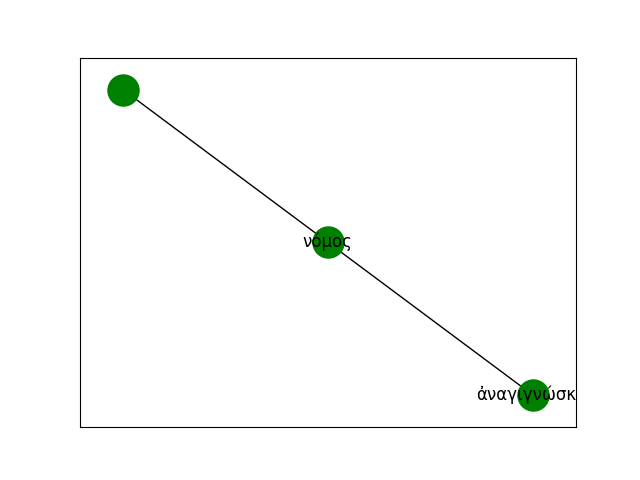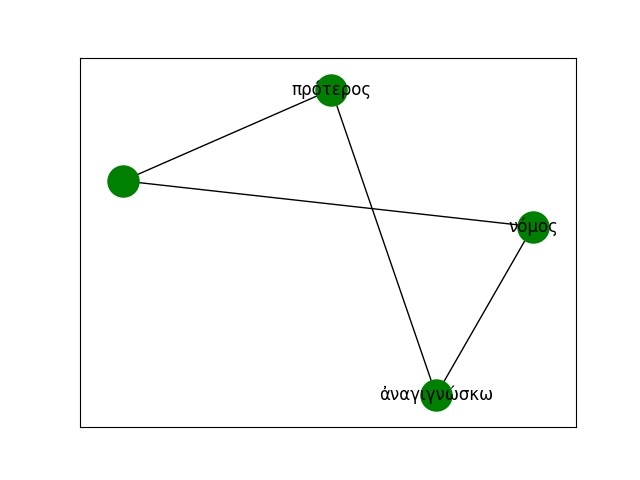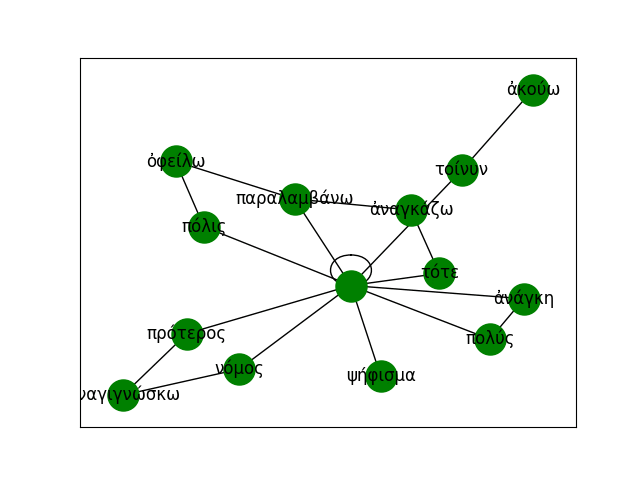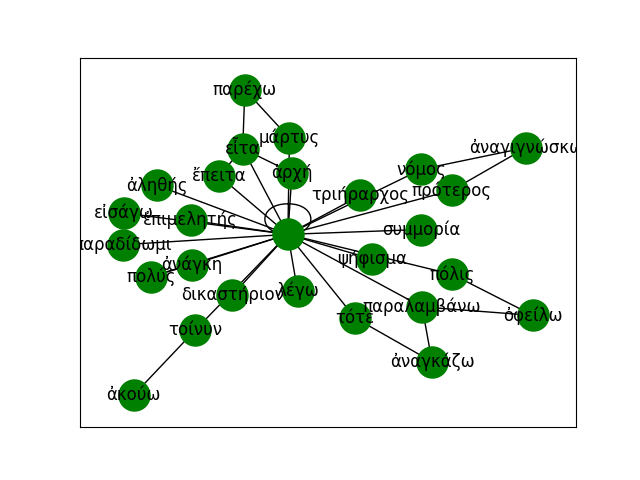
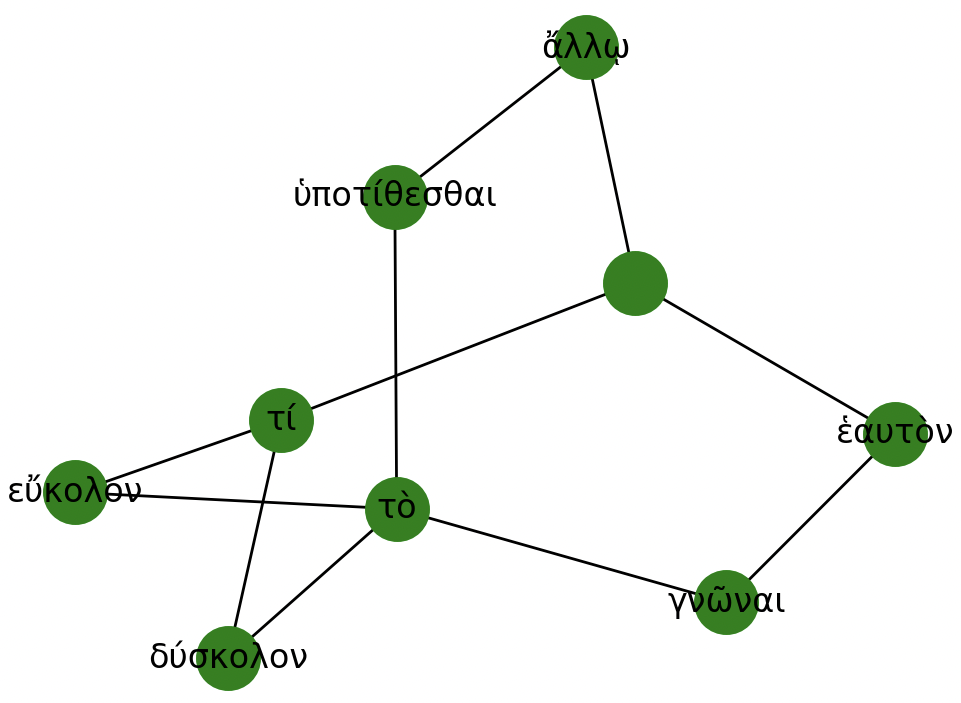
For example, given the following two sentences:
Τί δύσκολον; Τὸ ἑαυτὸν γνῶναι.
and
'What is hard? To know yourself.'τί εὔκολον; Τὸ ἄλλῳ ὑποτίθεσθαι.
'What is easy? To advise another.'Their dependency structures are converted into graphs and merged into a larger supergraph that captures syntactic relations across the corpus:
Data
The embeddings were trained using syntactically annotated sentences from several Ancient Greek treebanks available in XML format.Four of the sources follow the AGDT annotation scheme:
- Gorman Treebanks
- PapyGreek Treebanks
- Pedalion Treebanks
- The Ancient Greek Dependency Treebank (PerseusDL)
In addition, the Ancient Greek portion of the PROIEL treebanks was used:
- PROIEL Treebanks , annotated following the PROIEL scheme.
Data and preprocessing
Dependency relations in each treebank were converted into parenthetical tree structures, with separate conversion procedures for the AGDT and PROIEL annotation schemes. Stopwords were removed and lemmata were used instead of surface forms. The resulting trees were combined into a single graph structure following the supergraph framework. The preprocessing scripts can be found here.Training
Word embeddings were trained from the resulting graph using node2vec. The example shown below uses a window size of 5 and min_count = 1.
Results
The table below compares the five nearest neighbours of ἐλεύθερος ('free') in two vector spaces: a traditional count-based distributional model (PPMI) and the syntactic embedding model.
The count-based model retrieves words that are semantically or topically related to ἐλεύθερος, while the syntactic embeddings tend to retrieve words with similar grammatical distributions, such as other adjectives occurring in comparable syntactic contexts.
5-nearest neighbours for ἐλεύθερος 'free, freedom'
Count-based model Syntactic embeddings δοῦλος αἰσχρός ἐλευθερία λωίων δουλεύω εὐσχήμων πολίτης εὐτελής δεσπότης πλούσιος Credits
The neighbours from the count-based model shown in the table above were extracted from a model trained by Silvia Stopponi. The method presented here and other results from this experiment were presented in more details at the International Conference of Historical Linguistics (ICHL25, August 2022, Oxford, United Kingdom), in a paper titled Evaluating Language Models for Ancient Greek: Design, Challenges, and Future Directions . All the models mentioned here can be found on Zenodo.References
S. Stopponi, N. Pedrazzini, S. Peels-Matthey, B. McGillivray & M. Nissim. 2023. Evaluation of distributional semantic models of Ancient Greek: Preliminary results and a road map for future work. In Proceedings of the Ancient Language Processing Workshop, pages 49–58. Varna, Bulgaria: INCOMA Ltd., Shoumen, Bulgaria.
S. Stopponi, N. Pedrazzini, S. Peels-Matthey, B. McGillivray & M. Nissim. 2024. Natural language processing for Ancient Greek: Design, advantages and challenges of language models. Diachronica 41(3), pages 414-435.
S. Stopponi, N. Pedrazzini, S. Peels-Matthey, B. McGillivray & M. Nissim. 2023. Ancient Greek language models [Dataset]. Zenodo.
R. Al-Ghezi & M. Kurimo. 2020. Graph-based syntactic word embeddings. In Proceedings of the Graph-based Methods for Natural Language Processing (TextGraphs), pages 72–78. Barcelona, Spain (Online): Association for Computational Linguistics.
Check out other projects