Cross-Variety Dependency Parsing for Early Slavic
Challenge
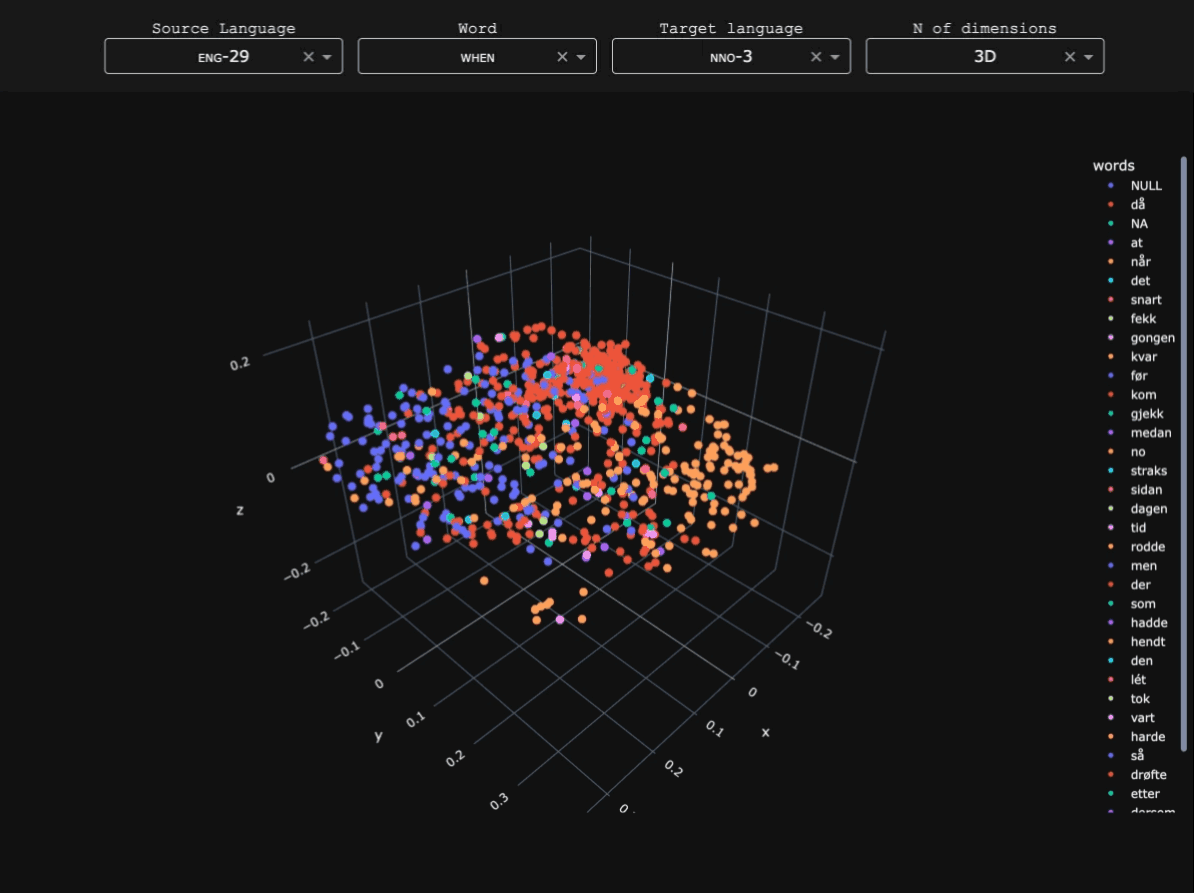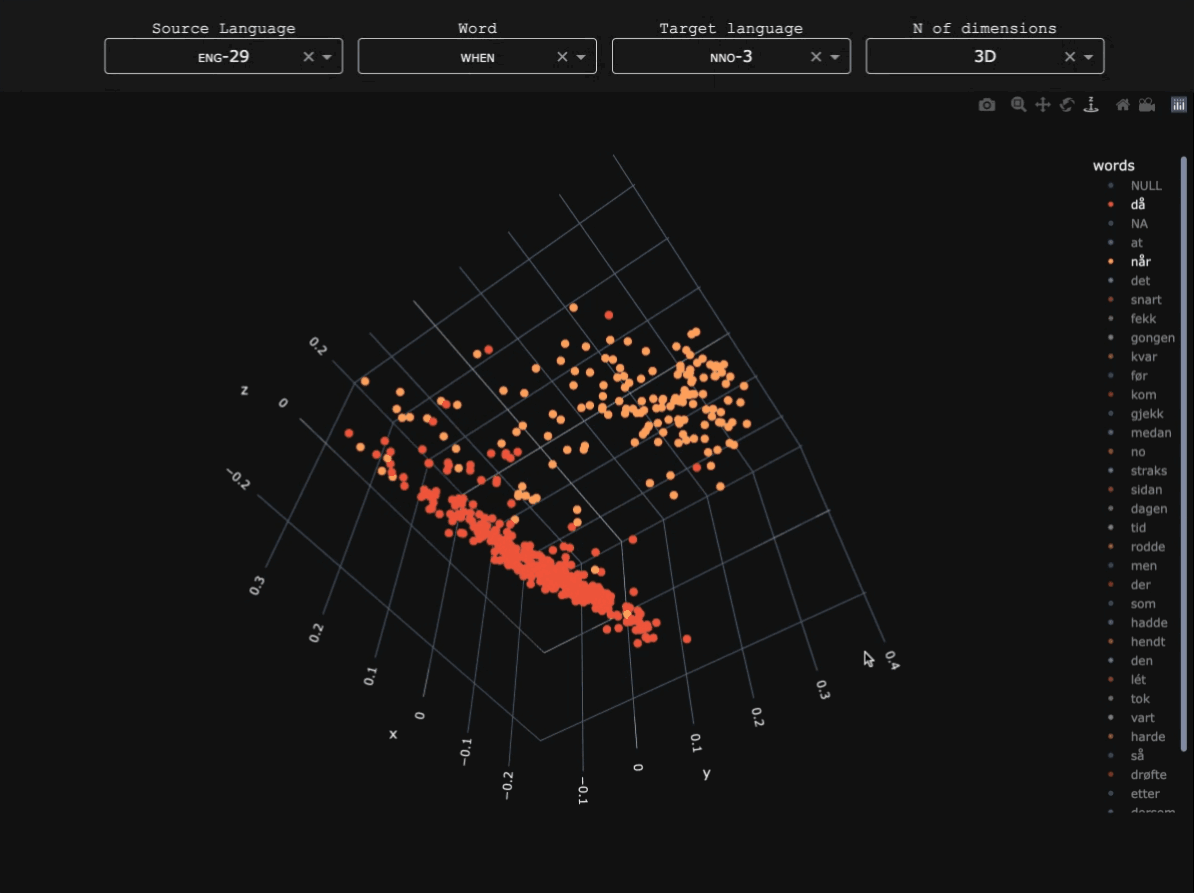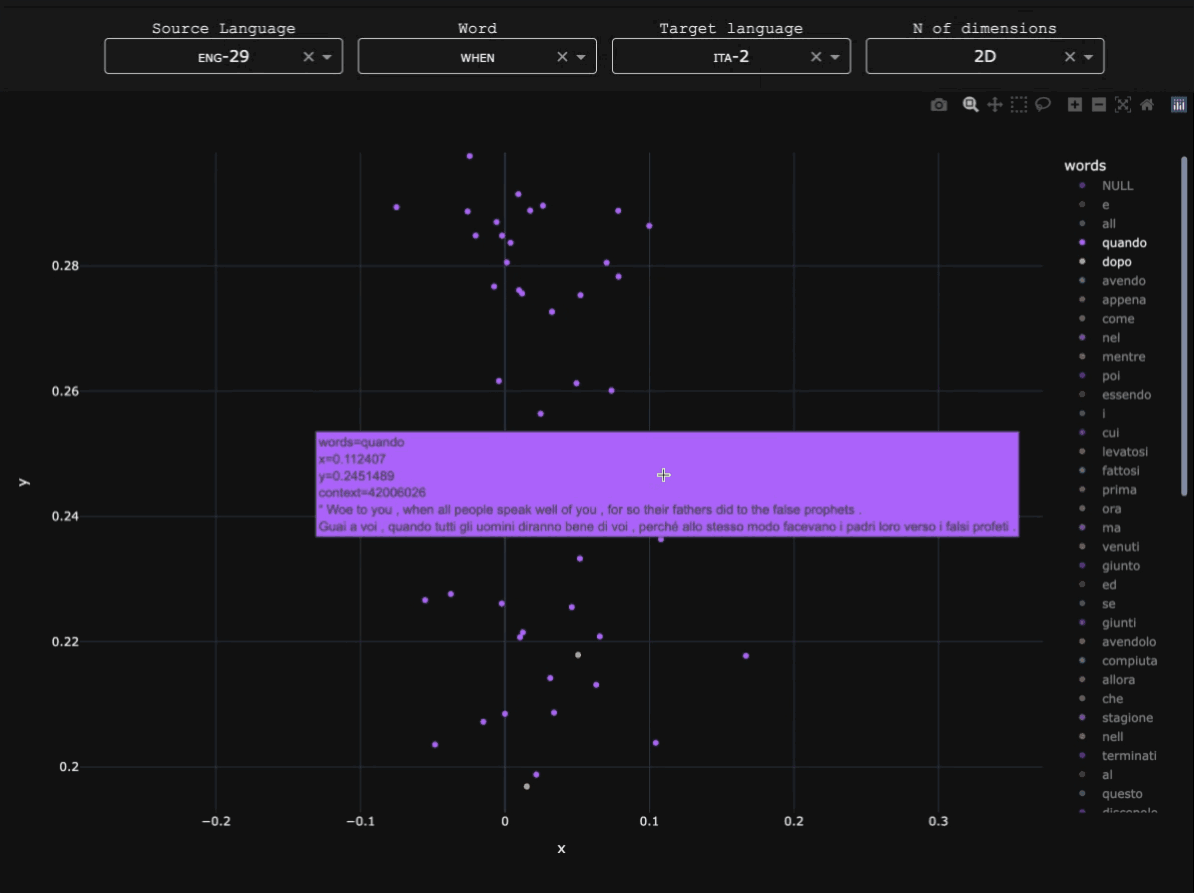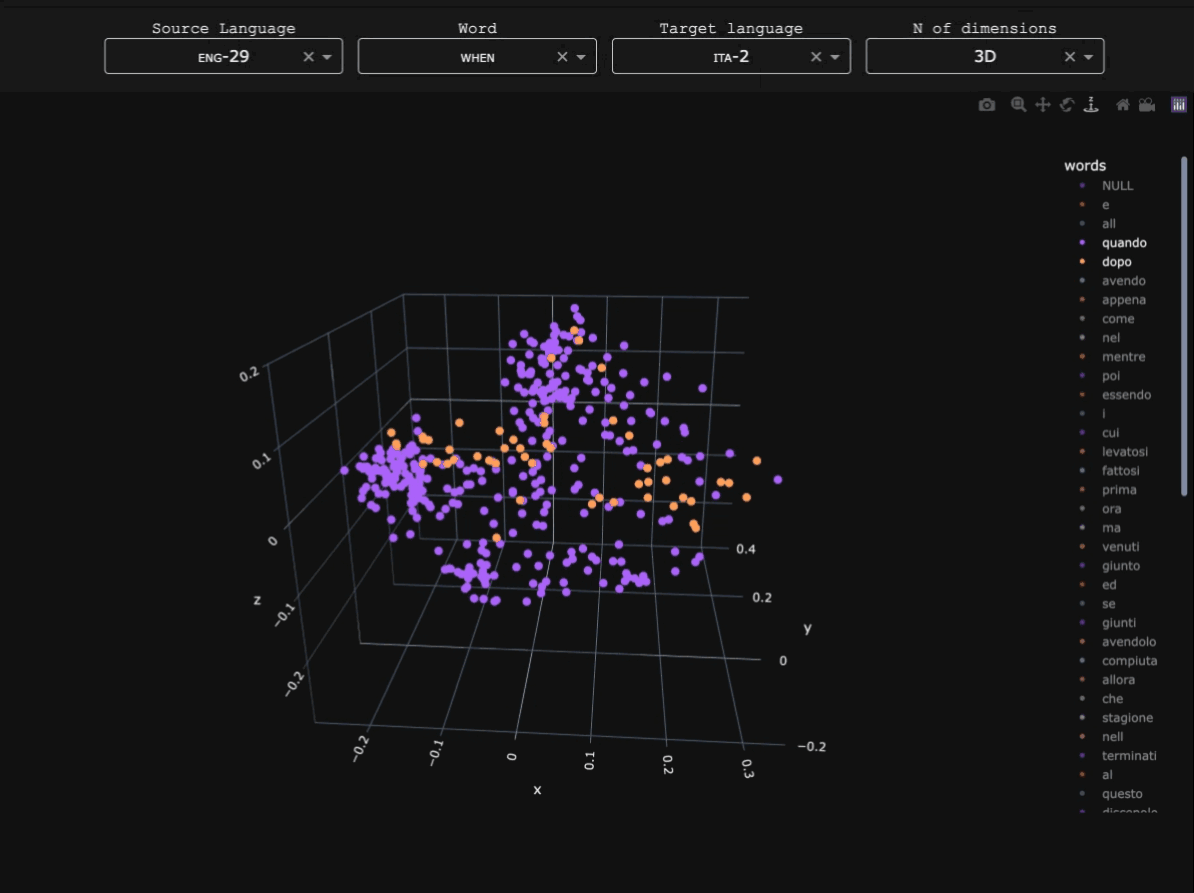
Pre-modern Slavic presents particular challenges for NLP. What is often treated computationally as single languages (e.g. 'Church Slavonic' or 'Old East Slavic') actually consists of multiple written varieties with different orthographic conventions, scribal practices, and regional norms. The cultural sphere of Slavia Orthodoxa was characterized for centuries by diglossia between Church Slavonic and local Slavic varieties, which led to most pre-modern texts containing features of both to varying degrees. This 'hybrid' nature of early Slavic introduces substantial variation and data sparsity, posing challenges for machine learning models trained on relatively small annotated corpora (see Schenker 1995 for an overview of early Slavic).Research questions
- Can the performance of variety-specific dependency parsers for Early Slavic be improved by incorporating training data from related written varieties?
- Is it possible to obtain a more robust 'generic' parser capable of handling the variation found across Early Slavic textual traditions?
- Given expert knowledge about the historical development of Slavic languages, can modern Slavic data be leveraged by normalizing their orthography and morphology so as to approximate pre-modern Slavic varieties?
Data
Early Slavic and Modern Russian data were obtained from the Tromsø Old Church Slavonic and Old Russian Treebanks (TOROT), including the full Church Slavonic and Old Russian subcorpora and part of the SynTagRus Modern Russian treebank. Modern Serbian data were taken from the Universal Dependencies Serbian-SET treebank. A detailed breakdown of token counts for each subvariety in the corpus is available here.Parser architecture
The parser was trained on CoNLL-U files within the Universal Dependencies framework. Its architecture is based on the neural joint parser of Nguyen et al. (2017), designed for morphology-rich languages such as Early Slavic. Only minor modifications were introduced:- ArgParse replaced the deprecated OptParse.
- RMSProp was used instead of Adam to improve training stability.
- The initial learning rate was fixed at 0.1.
Preprocessing and data split
- Each text was divided into training (80%), development (10%), and test (10%) data. Texts shorter than 400 tokens were used only for training.
- TOROT treebanks are distributed both in PROIEL XML and CoNLL formats. The datasets were converted to CoNLL-U using the proiel-cli utility.
- Modern Russian and Serbian data were orthographically and morphologically normalized to approximate Early Slavic forms using scripts provided here.
Models trained
Three models were trained in order to evaluate whether variety-specific parsers outperform a mixed model:- An East Slavic model trained exclusively on East Slavic texts.
- A South Slavic model trained exclusively on South Slavic texts.
- A generic model trained on mixed data from both varieties, including normalized modern Slavic texts.
Results
The generic model performs best overall, suggesting that pre-modern Slavic dependency parsing benefits from training on heterogeneous data rather than variety-specific models. In East Slavic texts, the generic parser surpassed the specialized model only after the addition of normalized modern Slavic data. A detailed discussion of the experiments can be found in Pedrazzini (2020) and Pedrazzini & Eckhoff (2021).Credits
The normalization scripts used to map Modern Russian and Serbian data to pre-modern Slavic forms were developed in collaboration with Dr Hanne Eckhoff (Oxford).References
A. M. Schenker. 1995. The Dawn of Slavic: An Introduction to Slavic Philology. New Haven, CT: Yale University Press.
H. M. Eckhoff & A. Berdicevskis. 2015. Linguistics vs. digital editions: The Tromsø Old Russian and OCS treebank. Scripta & e-Scripta, 14–15, pages 9–25.
A. Berdičevskis & H. M. Eckhoff. 2020. A diachronic treebank of Russian spanning more than a thousand years. In Proceedings of the 12th Language Resources and Evaluation Conference, pages 5251–5256. Marseille, France: European Language Resources Association.
T. Samardžić, M. Starović, Ž. Agić & N. Ljubešić. 2017. Universal Dependencies for Serbian in comparison with Croatian and other Slavic languages. In Proceedings of the 6th Workshop on Balto-Slavic Natural Language Processing, pages 39–44. Valencia, Spain: Association for Computational Linguistics.
D. Q. Nguyen, M. Dras & M. Johnson. 2017. A novel neural network model for joint POS tagging and graph-based dependency parsing. In Proceedings of the CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies, pages 134–142. Vancouver, Canada: Association for Computational Linguistics.
N. Pedrazzini. 2020. Exploiting cross-dialectal gold syntax for low-resource historical languages: Towards a generic parser for pre-modern Slavic . In F. Karsdorp, B. McGillivray, A. Nerghes & M. Wevers (eds.), Proceedings of the Workshop on Computational Humanities Research (CHR 2020), Vol. 2723, pages 237–247. Amsterdam, Netherlands: CEUR Workshop Proceedings.
N. Pedrazzini & H. M. Eckhoff. 2021. OldSlavNet: A scalable Early Slavic dependency parser trained on modern language data . Software Impacts, 100063.
N. Pedrazzini. 2023. Early Slavic word embeddings [Dataset]. Zenodo.
Check out other projects