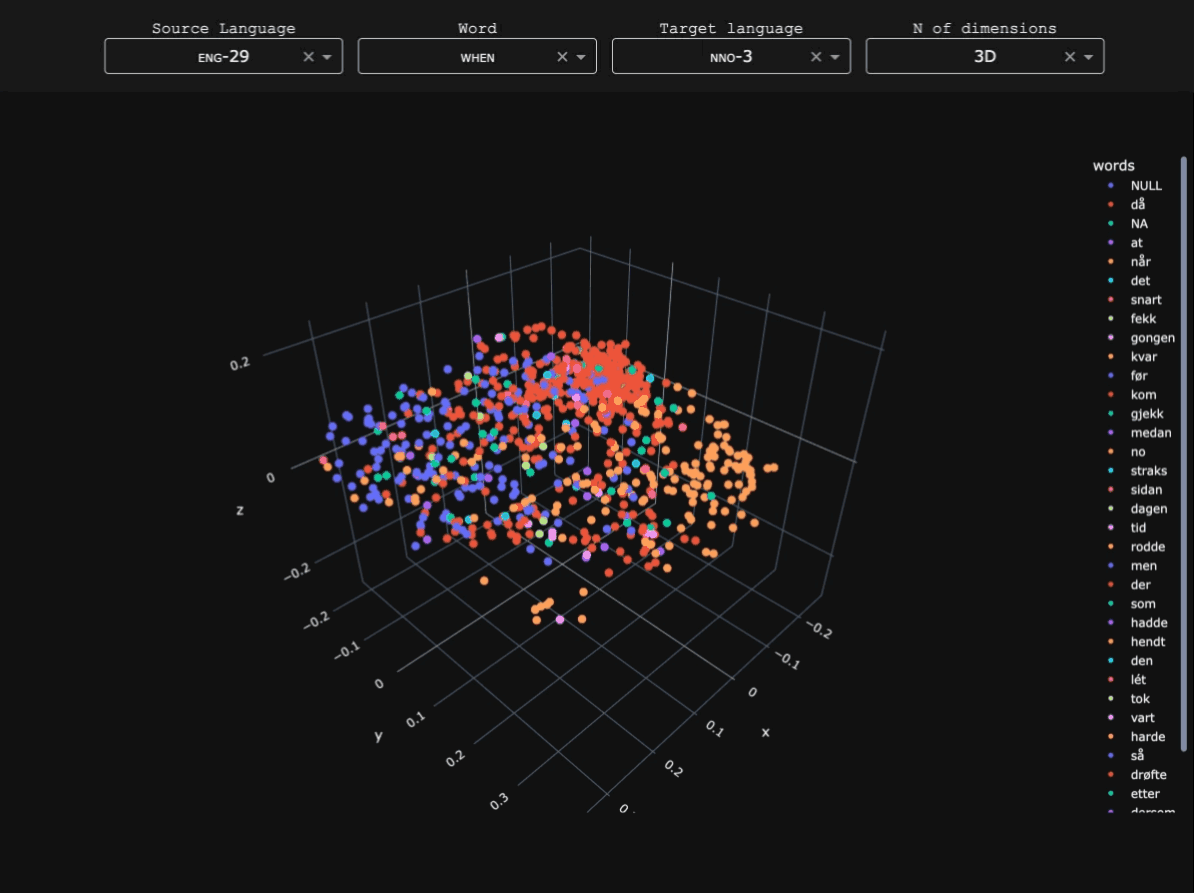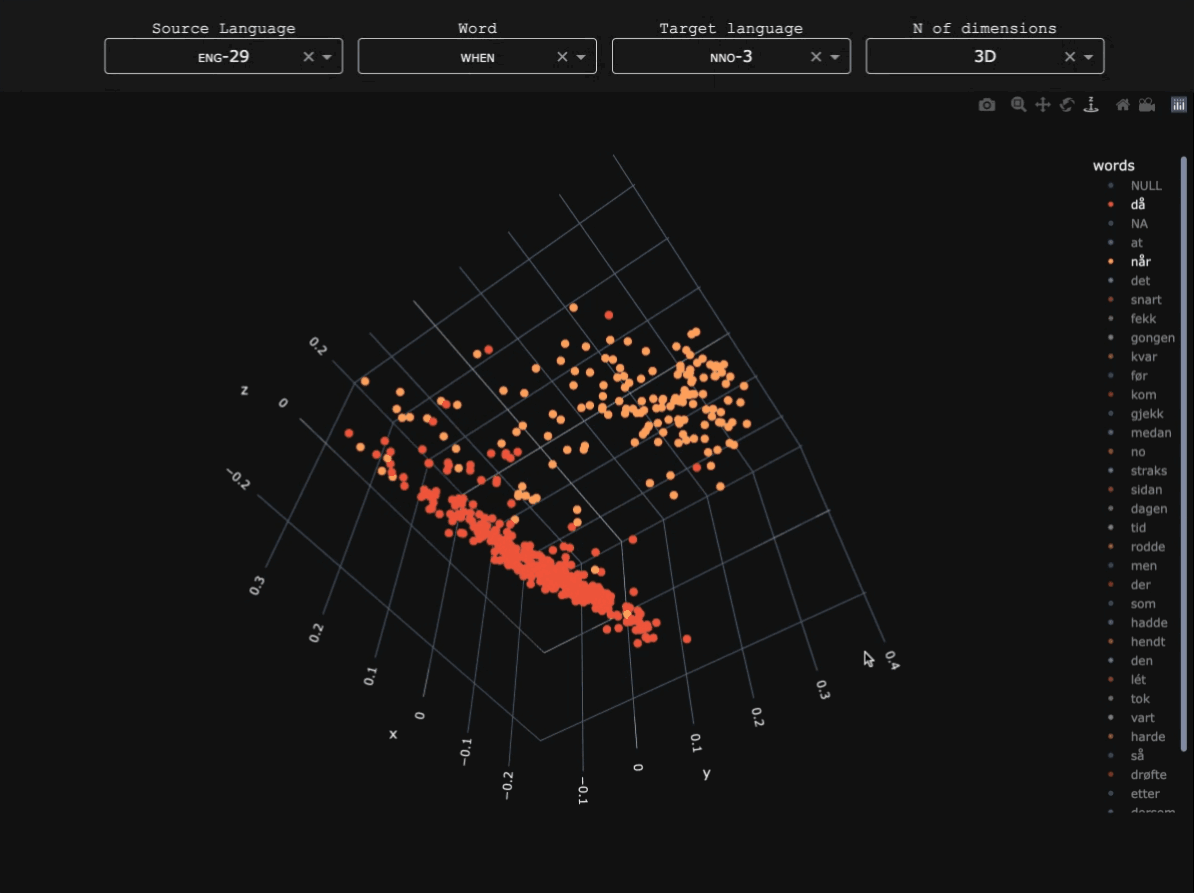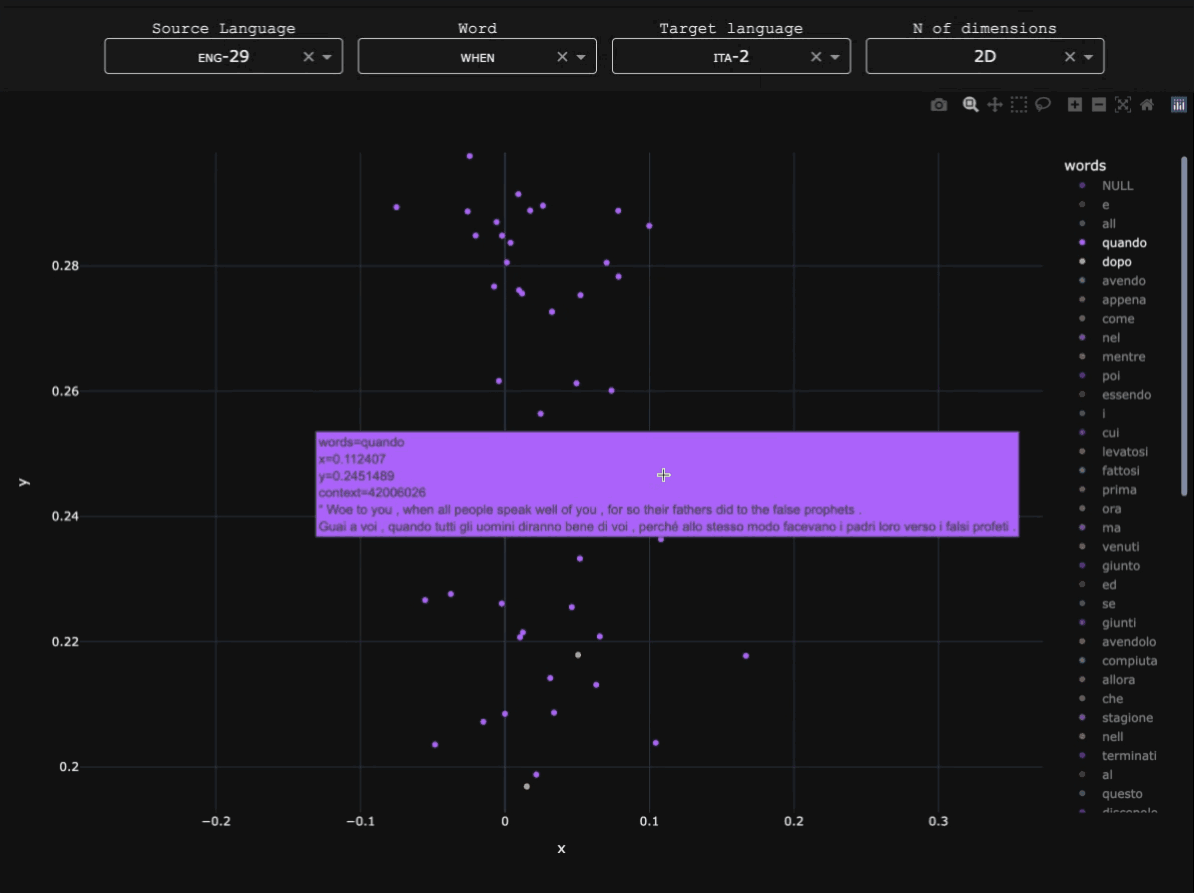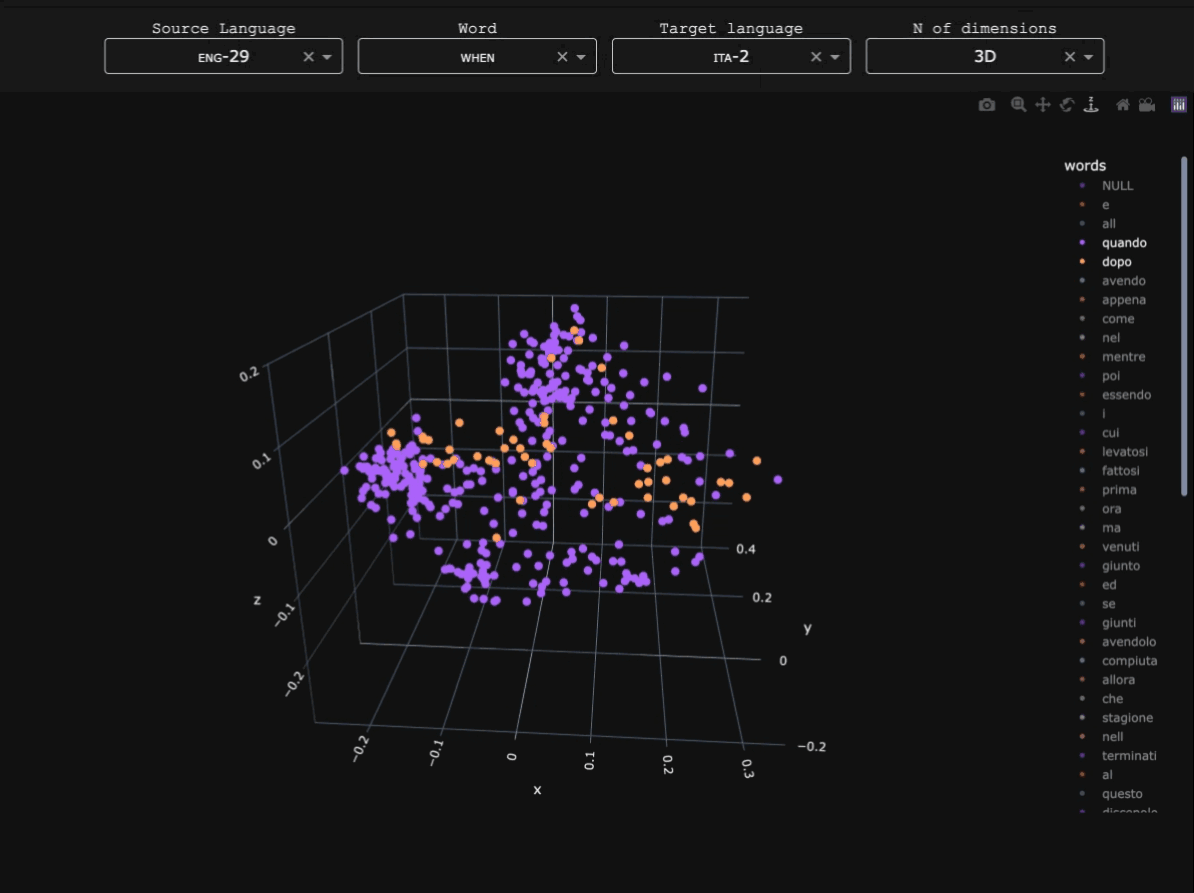
OldSlavNet
Challenge
Training good-quality dependency parsers for historical languages is a difficult task, since they normally provide very little data with very high levels of linguistic variation (lack of orthographic standards, dialectal dispersedness), which in machine learning easily translates into high levels of noise. Dependency parsing, however, is important in many downstream natural language processing (NLP) tasks, including event extraction, word vector representation enhancement, and text classification and summarization: solving this bottleneck can open new avenues in NLP for historical languages. Pre-modern Slavic is ideal to explore this issue, because of the multiple varieties it is represented by, each with their own orthographic conventions and scribal practices (i.e. sub-varieties are not necessarily homogeneous themselves) (see Schenker (1995) for an overview on Early Slavic).Questions
- To what extent can the performance of specialized (i.e. variety-specific) dependency parsers be improved by expanding the training set with data from other varieties and dialect areas?
- Is it possible to obtain a ‘generic’ parser, a tool which is relatively dialect-agnostic and more flexible with respect to genres and historical stages?
- Starting from expert knowledge on how Early Slavic varieties have evolved into modern Slavic languages, is it possible to leverage the much larger amount of data for the latter by normalizing/harmonizing their orthography and morphology to 'imitate' Early Slavic (as additional source of 'pre-modern' data)?
Data
Early Slavic and Modern Russian data was obtained from the Tromsø Old Church Slavonic and Old Russian Treebanks (TOROT) (specifically the entirety of its Church Slavonic and Old Russian subcorpus, and part of SynTagRus from its Modern Russian one), whereas Modern Serbian data was collected from the Universal Dependencies (UD) Serbian-SET treebank. Here you can find a detailed breakdown of the number of tokens for each subvariety (or 'dialect') in the corpus.Parser architecture
The parser is trained on CoNLL-U input files (of the UD framework), one of the most widely employed formats for dependency parsing. The tool’s neural-network architecture is based on jPTDP, since it was thought precisely for morphology-rich languages, such as Early Slavic, with a few adaptations:- ArgParse substitutes the older OptParse to allow for wider reusability of our code.
- RMSProp [8] is employed instead of Adam [9] as optimizer to avoid exploding gradients.
- The initial learning rate was set to 0.1 instead of None.
Preprocessing and train-dev-test split
- To reach representativeness and limit overfitting, 10% of each text was set aside as development data, 10% as test data and 80% as training data. Texts with fewer than 400 tokens were exclusively employed for training.
- TOROT treebanks come in two formats: the standard PROIEL XML format and the CoNLL-X format of UD. The datasets were converted from PROIEL XML to CoNLL-U using the script included in the Ruby utility proiel-cli, which can be used for the manipulation of PROIEL treebanks. The main differences between CoNLL-U and CoNLL-X are the treatment of multiword tokens as integer ranges and the insertion of comments before each new sentence, besides the different order and outlook of their morphotags (e.g. NUMBs|GENDn|CASEn in CoNLL-X and Case=Nom|Gender=Neut|Number=Sing in CoNLL-U).
- Modern Serbian and Modern Russian texts were normalized (or 'harmonized') using the scripts I provided here.
Models trained
Three main models were trained, to check whether a parser trained on a specific language variety would perform better than a generic one:- A specialized East-Slavic model, trained only on data from East Slavic texts.
- A specialized South-Slavic model, trained only on data from South Slavic texts.
- A generic model, trained on mixed data from both varieties, including normalized modern texts.
Results
The generic model performs better across the board, indicating that, because of data sparsity, Early Slavic dependency parsing is best achieved without training specialized models for separate varieties. See the performance of OldSlavnet compared to previous experiments: Note that on East Slavic texts, the generic parser superseded the specialized one in performance only after the addition of normalized modern texts. You can follow this rather complex discussion by reading (in order) Pedrazzini (2020) and Pedrazzini & Eckhoff (2021).Credits
The normalization scripts from Modern Russian and Modern Serbian to Early Slavic were written in collaboration with Dr Hanne Eckhoff (Oxford).References
A. M. Schenker. 1995. The Dawn of Slavic: An Introduction to Slavic Philology. Yale University Press.
H. M. Eckhoff and A. Berdicevskis. 2015. 'Linguistics vs. digital editions: The Tromsø Old Russian and OCS Treebank'. Scripta & e-Scripta 14–15, pp. 9-25.
A. Berdičevskis, H. M. Eckhoff. 2020. A Diachronic Treebank of Russian spanning more than a thousand years. Proceedings of the 12th Language Resources and Evaluation Conference, European Language Resources Association, Marseille, France, pp. 5251-5256.
T. Samardžić, M. Starović, Ž. Agić, N. Ljubešić. 2017. Universal Dependencies for Serbian in comparison with Croatian and other Slavic languages. Proceedings of the 6th Workshop on Balto-Slavic Natural Language Processing, Association for Computational Linguistics, Valencia, Spain, pp. 39-44
N. Pedrazzini. 2020. Exploiting cross-dialectal gold syntax for low-resource historical languages: Towards a generic parser for pre-modern Slavic. In F. Karsdorp, B. McGillivray, A. Nerghes, & M. Wevers (Eds.), Proceedings of the Workshop on Computational Humanities Research (CHR 2020) (Vol. 2723, pp. 237–247). Amsterdam, Netherlands: CEUR Workshop Proceedings
N. Pedrazzini, & H. M. Eckhoff. 2021. OldSlavNet: A scalable Early Slavic dependency parser trained on modern language data. Software Impacts, 100063.
Check out other projects