Projects and Research Areas
Linguistics
My linguistics training had a strong historical component, with a focus on Slavic and wider Indo-European. I use quantitative and computational approaches to investigate linguistic phenomena with a focus on:
- semantics of non-finite clauses
- typology of subordination
- discourse representation
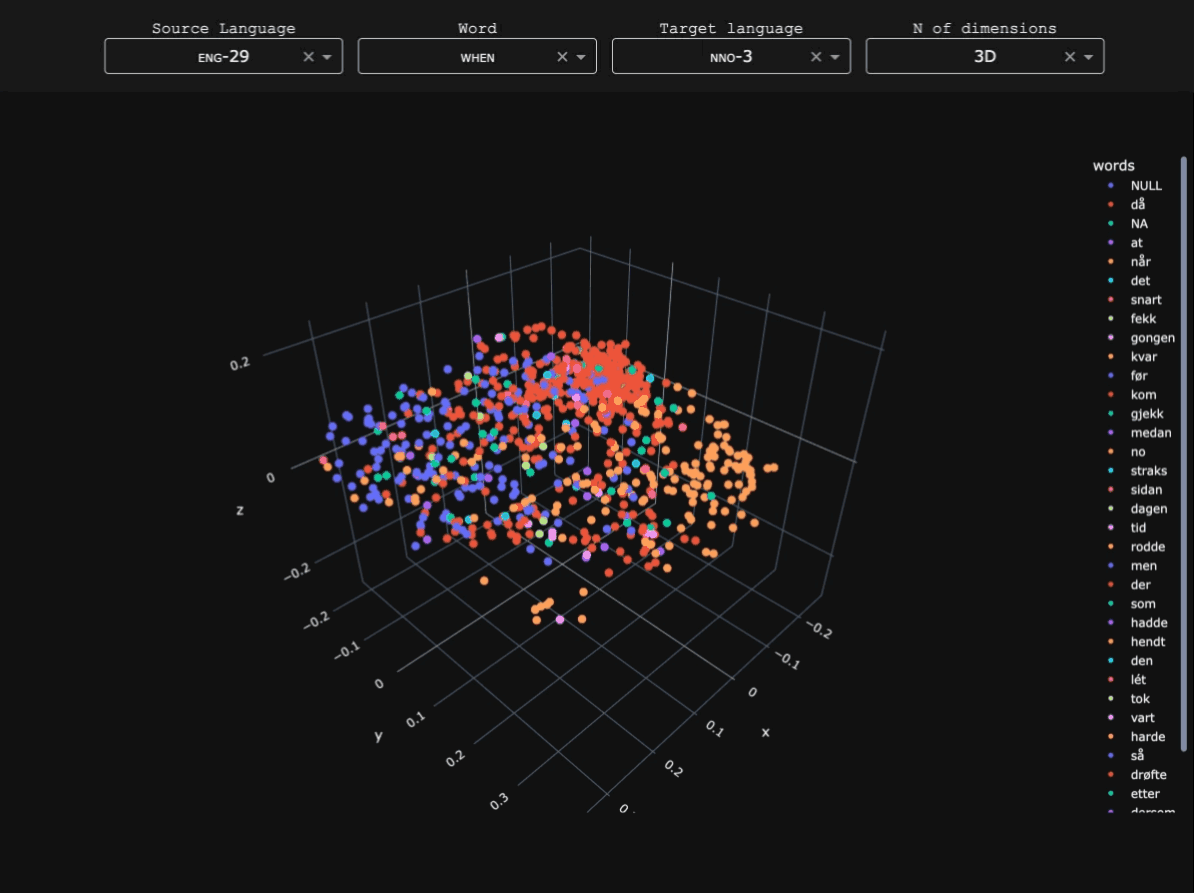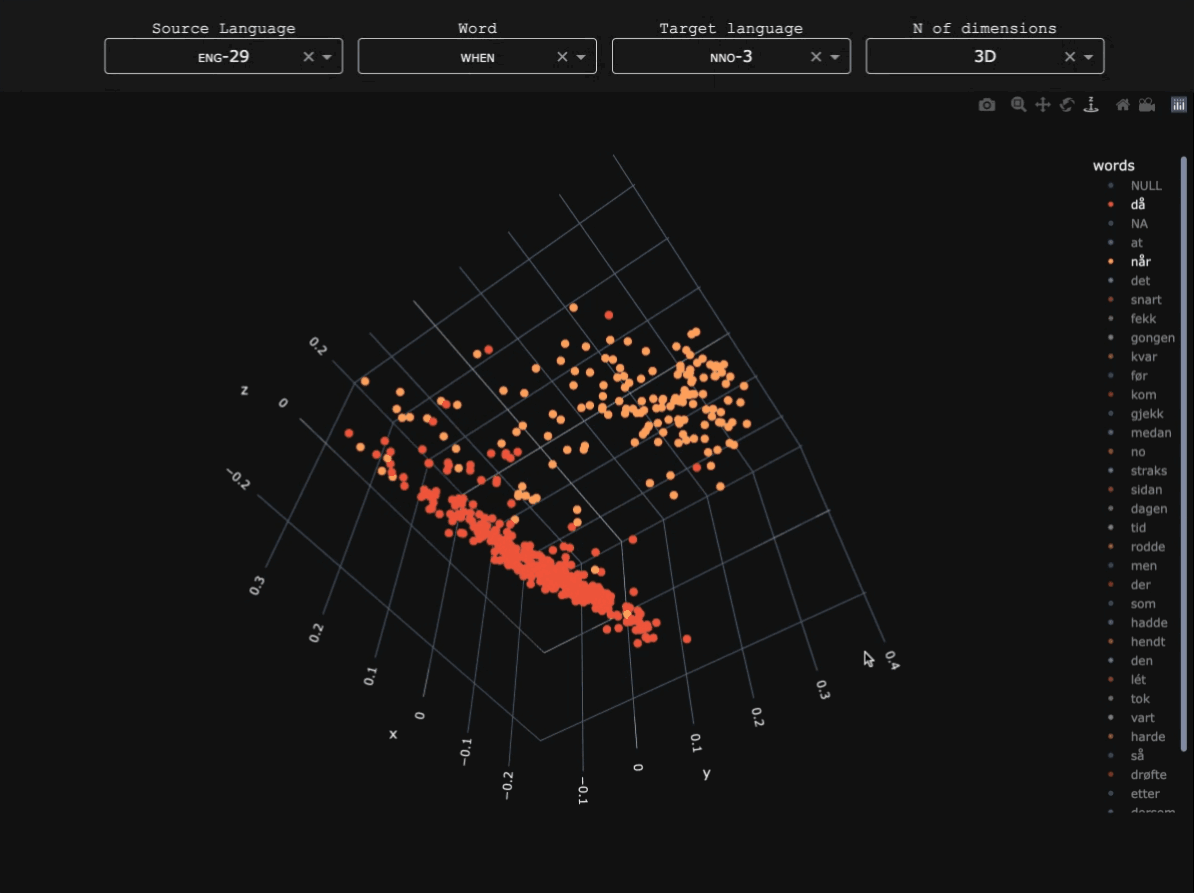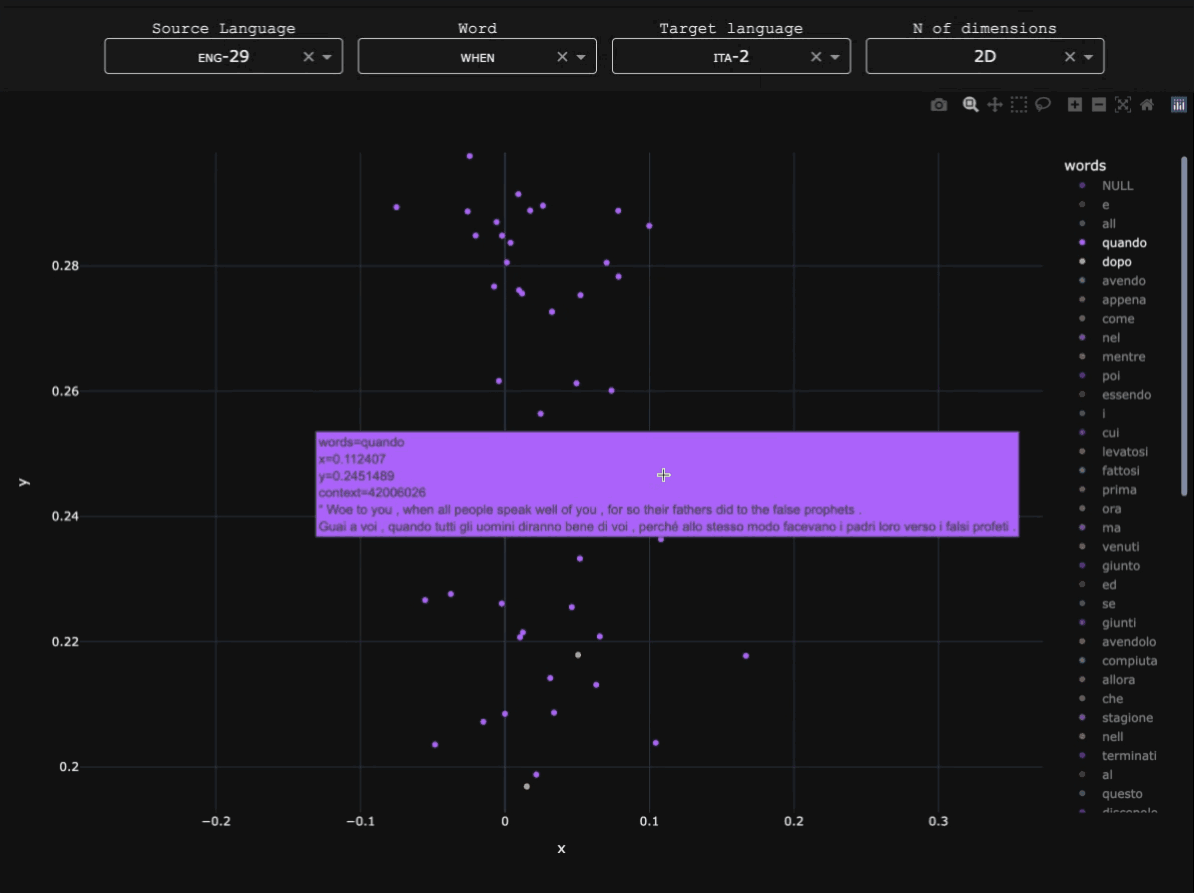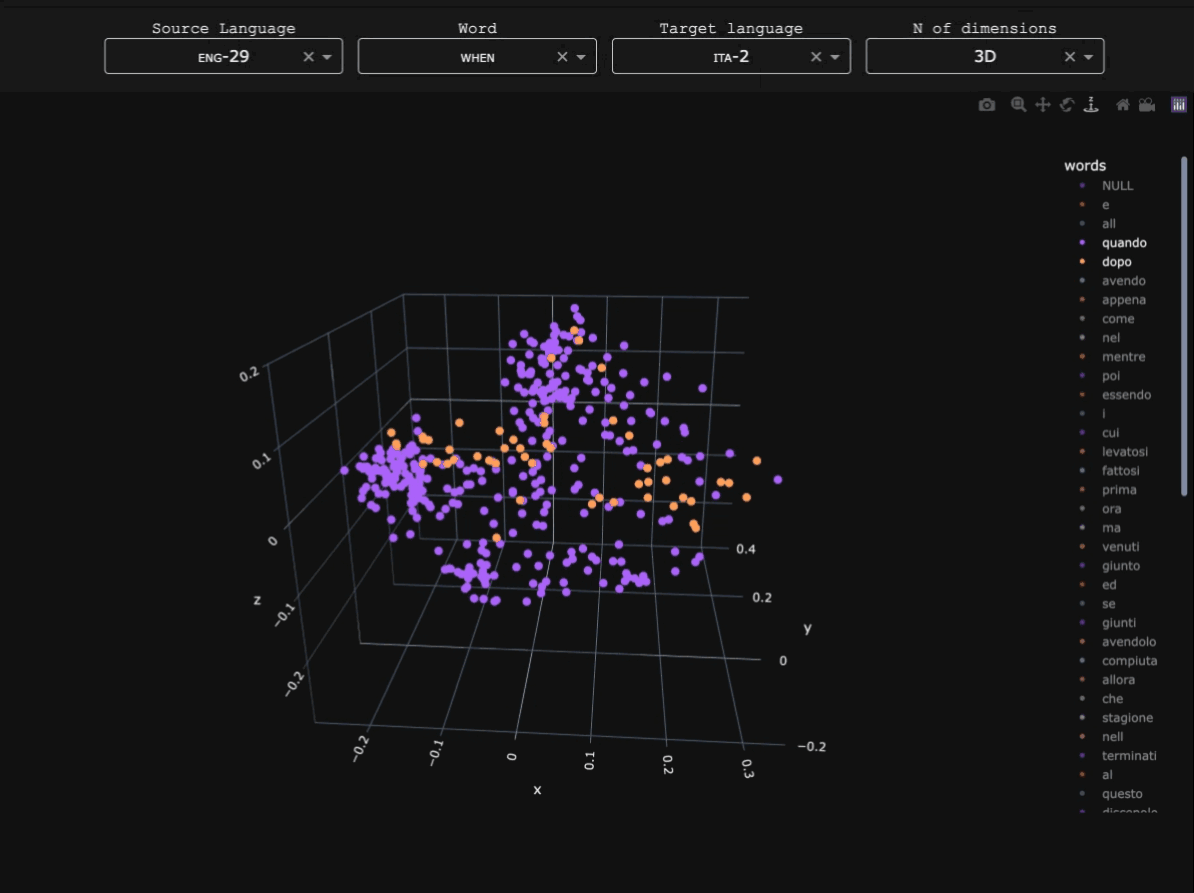
My doctoral project looked (quantitatively, through treebank data) into the competition between finite and non-finite temporal subordinates in Early Slavic, and their position within the typology of when-clauses in 1400+ languages.
Computational Humanities
It’s hard to set Computational Humanities apart from my main areas of research, and that’s often true for computational humanists at large: one tends to approach CH to answer questions in their research areas, and then may find themselves wondering about CH tools and techniques as such. The following are some of the areas I have worked in:
- application of NLProc methods to answer humanities research questions (language modelling, causal analysis, automatic linguistic annotation)
- application of computational methods from outside the humanities to humanities research (geostatistics, genetics, biology, you name it)
- visualization of (small and big) parallel language data
- corpus building, treebanking
Some of my contributions include:
- Mapping when-clauses in Latin American and Caribbean languages: an experiment in subtoken-based typology. Using character n-gram associations between English when and parallel texts in indigenous Latin American languages to understand the temporal subordination strategies used in the region. Published in the ACL Anthology as part of the Proceedings of the Workshop on Natural Language Processing for Indigenous Languages of the Americas (AmericasNLP).
- Training and evaluation of distributional semantic models of Ancient Greek (collaborative project, led by Silvia Stopponi, and with Saskia Peels-Matthey, Barbara McGillivray, and Malvina Nissim). Check out the papers Natural language processing for Ancient Greek: Design, advantages and challenges of language models (2024) and Evaluation of Distributional Semantic Models of Ancient Greek: Preliminary Results and a Road Map for Future Work (2023) (both with Silvia Stopponi, Saskia Peels-Matthey, Barbara McGillivray ad Malvina Nissim), where I dealt with syntactic (graph-based) embeddings.
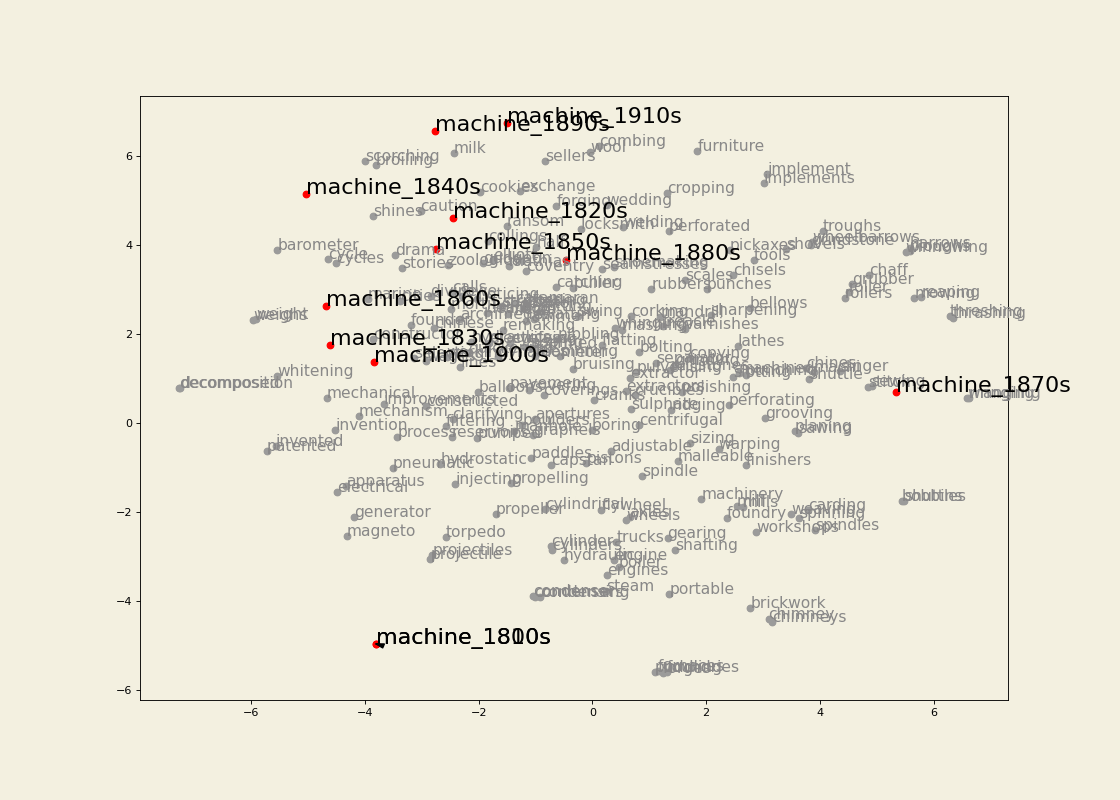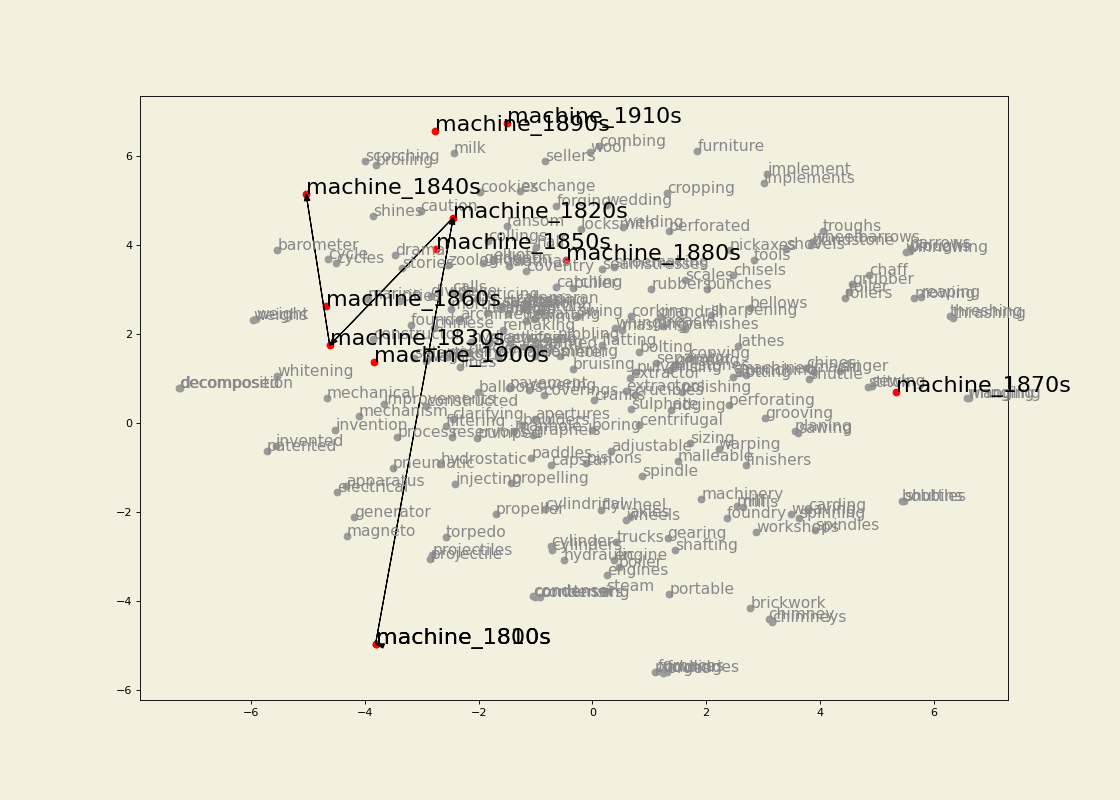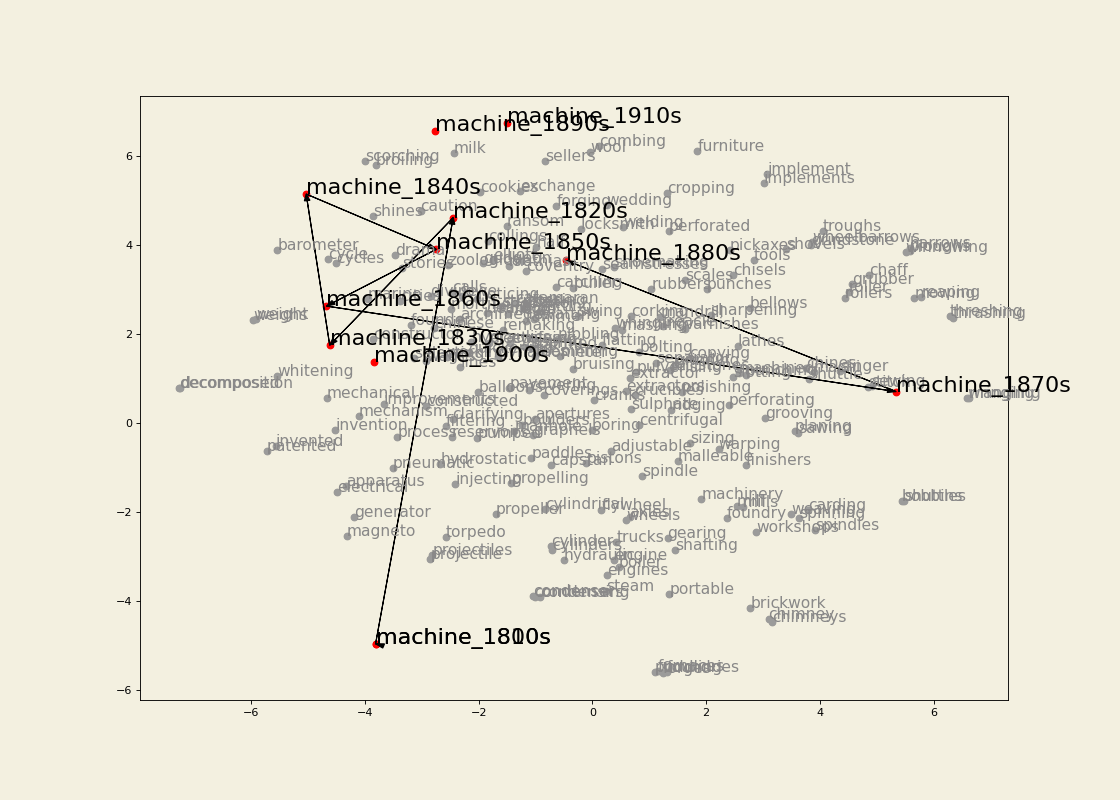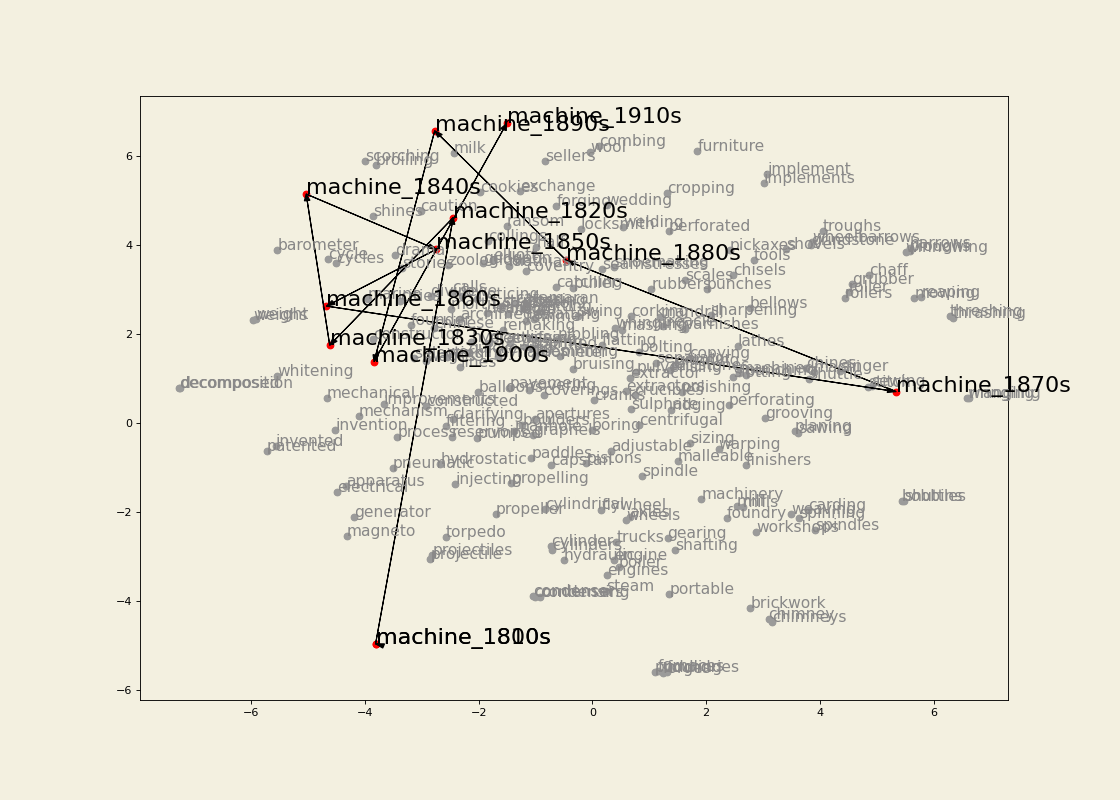
- Diachronic word embeddings from large-scale digitized historical data (19th century English). See here for the tools. Also check out a case study using the diachronic embeddings in the article Machines in the media: semantic change in the lexical field of mechanization in 19th-century British newspapers (with Barbara McGillivray).
- Early Slavic dependency parsing (see OldSlavNet and Publications).
Open Scholarship in the Humanities
I’m interested in the specific challenges faced by the Humanities in making research reproducible. Between 2020 and 2022 I was a Fellow at RROx, the Oxford ‘branch’ of the UK Reproducibility Network (UKRN) and Editorial Assistant for the Journal of Open Humanities Data (JOHD).
Some of my contributions to the discussion:
- The 2025 article Le Journal of Open Humanities Data (JOHD) : enjeux et défis dans la publication de data papers pour les sciences humaines et sociales (SHS), coauthored with Paola Marongiu (main author), Marton Ribary & Barbara McGillivray, based on work presented at DHord in 2020.
- The Open Humanities Seminar Series (OHSS), a monthly event I organized and ran from January to April 2022, dedicated to different aspects of Open Humanities.
- Deep Impact: A study on the impact of data papers and datasets in the humanities and social sciences (2022) with Barbara McGillivray, Marton Ribary, Mandy Wigdorowitz and Eleonora Zordan, presented at SciDatCon-IDW Seoul 2022 and published in Publications (Best Paper Award 2024).
Selected past contributions in collaborative projects
Quartz Solar AI nowcasting (The Alan Turing Institute)
As part of a secondment to the Research Engineering Group at The Alan Turing Institute, between August 2024 and January 2025 I worked within the Quartz Solar AI Nowcasting project in a research software engineering capacity. The project was a collaboration between the Turing Institute and the non-profit climate-tech company Open Climate Fix and aimed to improve solar power forecasts and enable more efficient integration of solar energy into the electricity grid by using generative AI to increase the accuracy of short-term cloud cover prediction (‘nowcasting’), as part of a wider effort to reduce costs and carbon emissions.
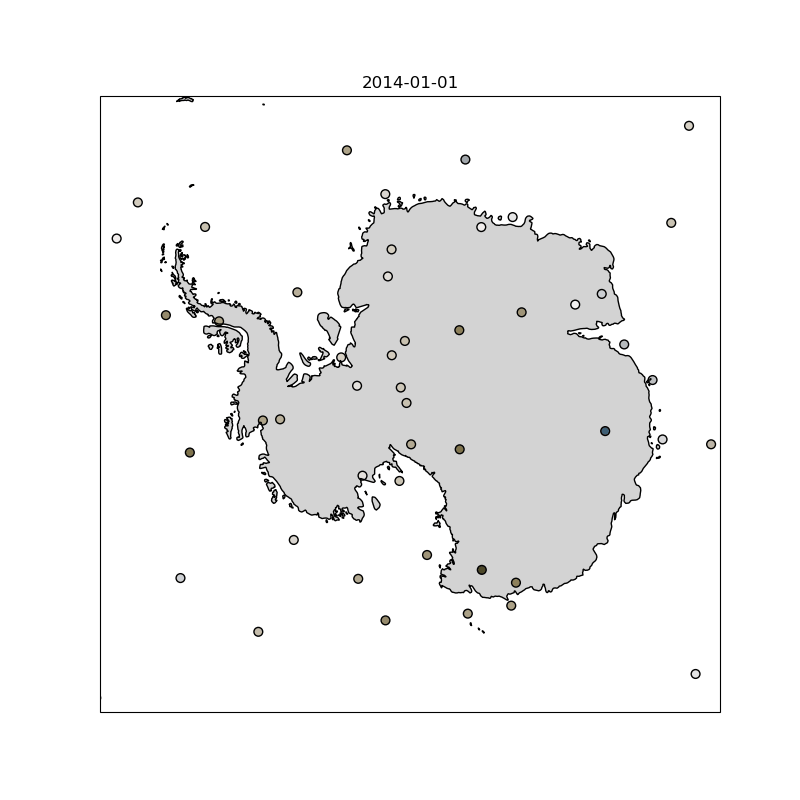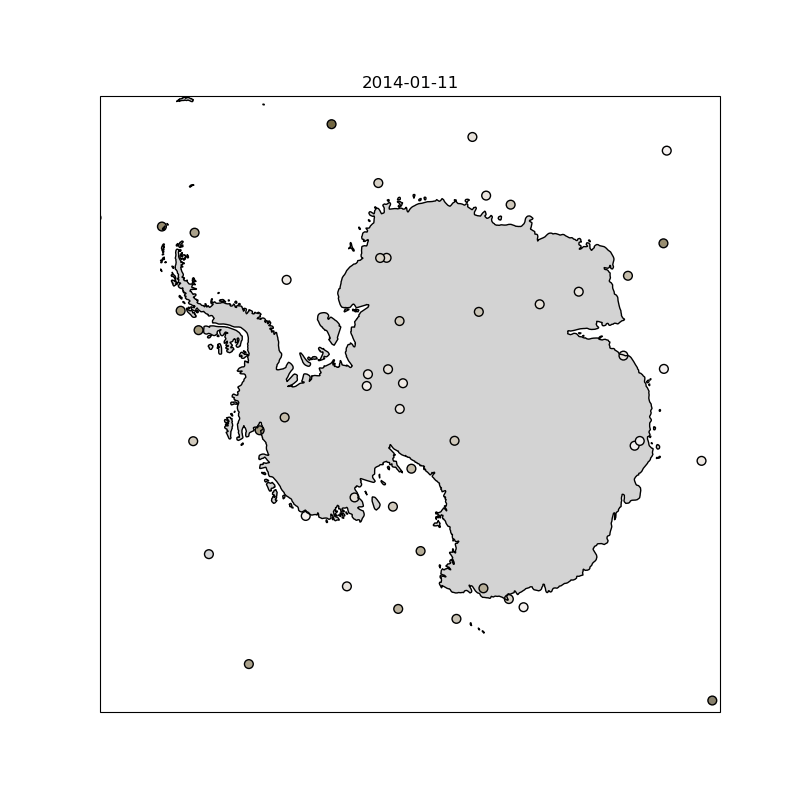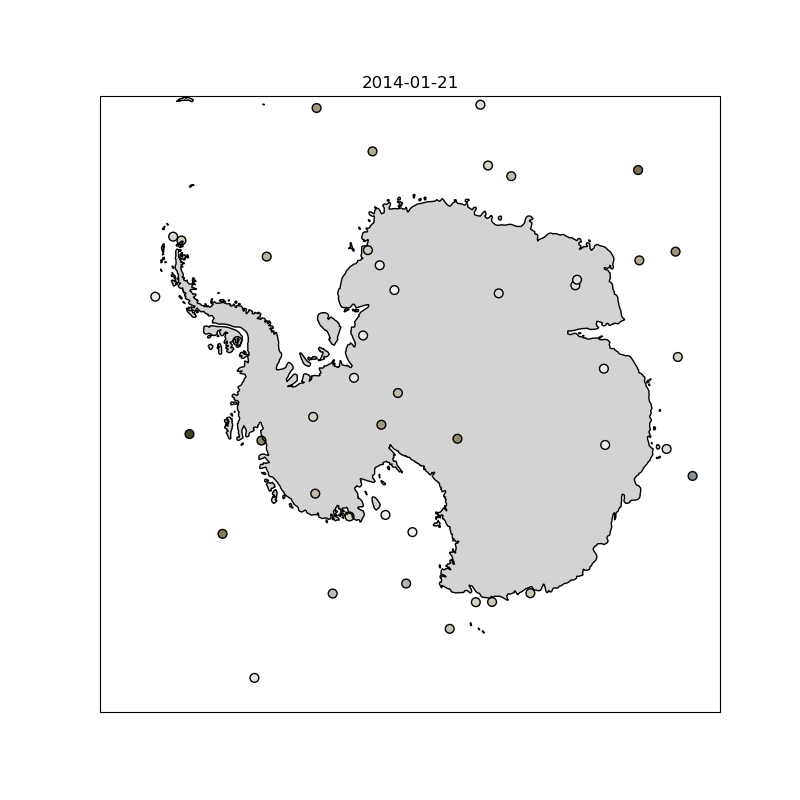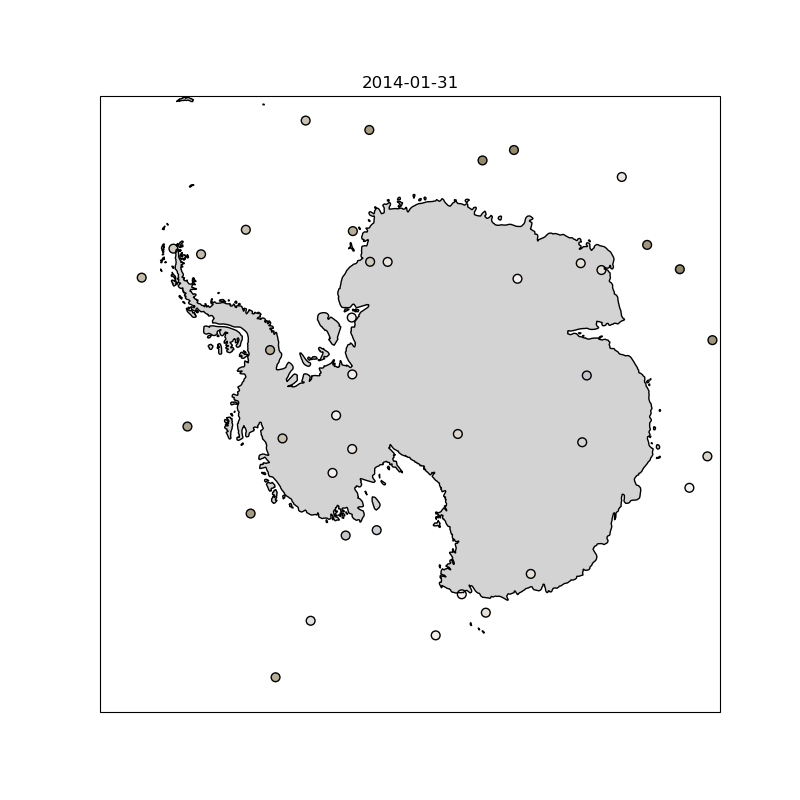
As part of this work, I trained a Transformer-based model (Earthformer ) that takes in 12 satellite images of cloud cover at 15-minute intervals and predicts the next 12, using data from 11 different spectral channels. While not intended as a novel architecture in itself, this model was one of several approaches the team implemented and compared as part of a broader suite of cloud nowcasting models. The animation below shows an example prediction from the model I trained.

Left: model prediction | Middle: ground truth | Right: difference
Living with Machines (The Alan Turing Institute)
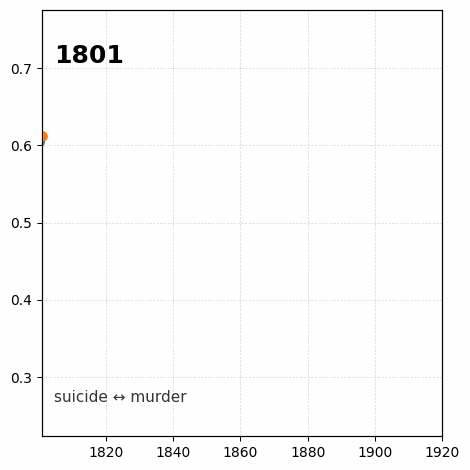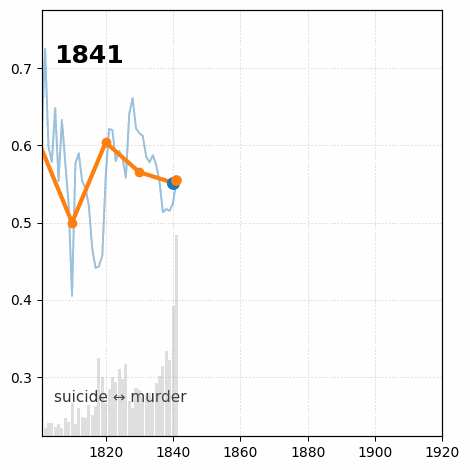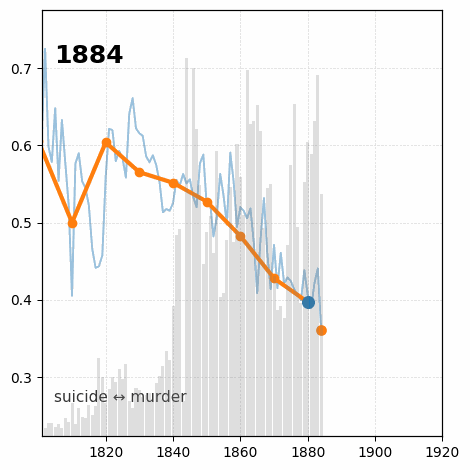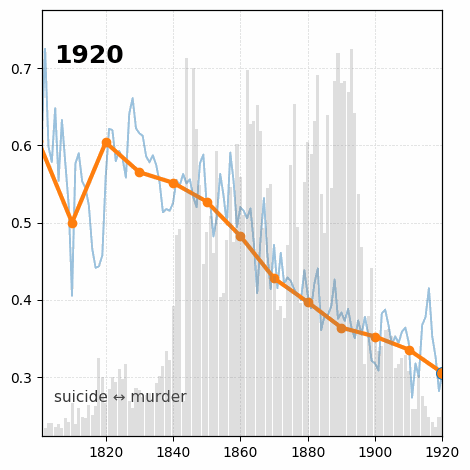
Between January 2022 and July 2023 I was Research Associate in the Living with Machines (LwM) project at The Alan Turing Institute. The overarching goal of LwM was to investigate the impact of technology on the lives of ordinary people during the Industrial Revolution. My job consisted in analyzing a very large amount of (very noisy) historical British newspaper data computationally, with a focus on looking into how language use changed throughout the 19th century as an effect of the socio-political changes following the Industrial Revolution. See here for an example of results from my research.
Also check out below two episodes of a docuseries on Living with Machines, where my colleages and I talk about collaboration in large interdisciplinary projects in the Humanities and the Language of Mechanization subprojects in which I was involved.
On collaboration:
On the Language of Mechanization:
Depictions of Post-COVID-19 Futures in Russian International Media: Multimodal Viewpoint Analysis (IMCC, University of Oxford)
Starting from mid-2020, I was a Research Assistant at the International Multimodal Communication Centre (IMCC) based within the Oxford School of Global and Area Studies (OSGA) at the University of Oxford. I carried out annotation and correlation analyses of speech-gesture co-occurrences in Russian and American media, largely within the project Depictions of Post-COVID-19 Futures in Russian International Media: Multimodal Viewpoint Analysis .
ReadOxford (University of Oxford, Department of Experimental Psychology)
In 2020 I spent two months as a Research Assistant at the ReadOxford research group, based at the Department of Experimental Psychology of the University of Oxford. The aim of the group is to answer different questions related to child literacy development. I mainly dealt with data processing, developing R scripts to make corpus data reproducible and analysable for morphological complexity and lexical variation. My major contribution has been scripting an R code to automatically calculate the Average Reduced Frequency (ARF) of combined lemmata/parts of speech in the Oxford Children Corpus and Childes treebank.
Enhancing catalogue metadata of Slavonic early-printed Cyrillic books (British Library)
In 2015, I spent two months as a trainee Assistant Curator-Cataloguer for the Slavonic Collections at The British Library . During that time, I enhanced the online catalogue of all Slavonic early-printed Cyrillic books held at the British Library (and fuelled my interest for all-things data and pre-modern Slavic). Check out two posts I wrote for the British Library’s European Studies Blog:
- Fairytales on trial: the Good and the Beautiful in early-Soviet children’s literature (26th March 2019)
- A reluctantly modern voice from the 17th-century Russian storm: Archpriest Avvakum and the Lifewritten by himself (10 June 2015)
Zoom in on some of my projects